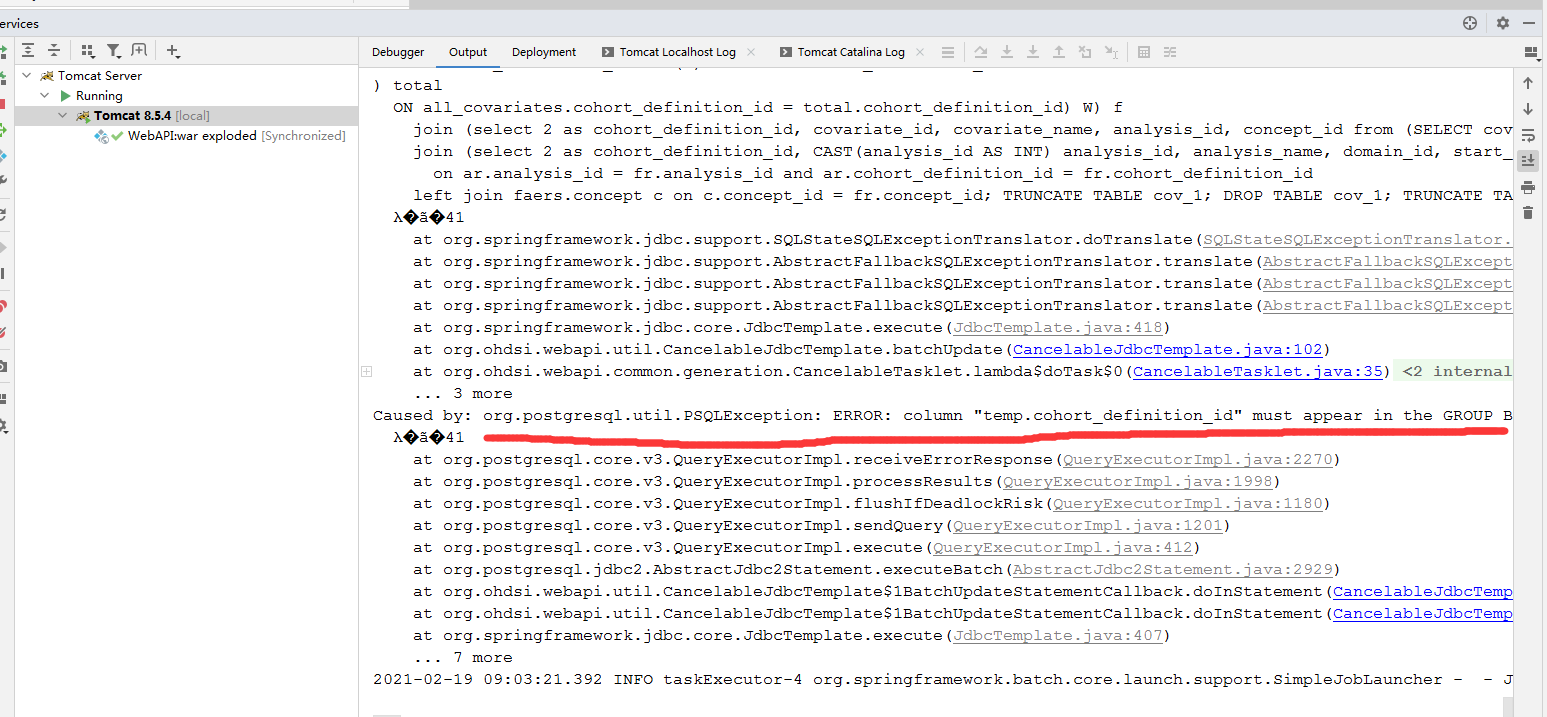
org.ohdsi.webapi.exception.AtlasException: java.lang.RuntimeException: java.util.concurrent.ExecutionException: org.springframework.jdbc.BadSqlGrammarException: StatementCallback; bad SQL grammar [DROP TABLE IF EXISTS cov_ref; DROP TABLE IF EXISTS analysis_ref; CREATE TEMP TABLE cov_ref (covariate_id BIGINT,
covariate_name VARCHAR(512),
analysis_id INT,
concept_id INT
); CREATE TEMP TABLE analysis_ref (analysis_id BIGINT,
analysis_name VARCHAR(512),
domain_id VARCHAR(20),
start_day INT,
end_day INT,
is_binary VARCHAR(1),
missing_means_zero VARCHAR(1)
); DROP TABLE IF EXISTS concept_count_data; DROP TABLE IF EXISTS concept_count_stats; DROP TABLE IF EXISTS concept_count_prep; DROP TABLE IF EXISTS concept_count_prep2; CREATE TEMP TABLE concept_count_data
AS
SELECT
cohort_definition_id,
subject_id,
cohort_start_date,
concept_count
FROM
(
SELECT
cohort_definition_id,
subject_id,
cohort_start_date,
COUNT(*) AS concept_count
FROM results.temp_cohort_oflsq4ja cohort
INNER JOIN faers.visit_occurrence
ON cohort.subject_id = visit_occurrence.person_id
WHERE visit_start_date <= (cohort.cohort_start_date + 0*INTERVAL'1 day')
AND visit_end_date >= (cohort.cohort_start_date + -180*INTERVAL'1 day')
AND visit_concept_id != 0
AND cohort.cohort_definition_id IN (2)
GROUP BY
cohort_definition_id,
subject_id,
cohort_start_date
) raw_data; ANALYZE concept_count_data
; CREATE TEMP TABLE concept_count_stats
AS
WITH t1 AS (
SELECT cohort_definition_id,
COUNT(*) AS cnt
FROM results.temp_cohort_oflsq4ja
WHERE cohort_definition_id IN (2)
GROUP BY cohort_definition_id
),
t2 AS (
SELECT cohort_definition_id,
COUNT(*) AS cnt,
MIN(concept_count) AS min_concept_count,
MAX(concept_count) AS max_concept_count,
SUM(CAST(concept_count AS BIGINT)) AS sum_concept_count,
SUM(CAST(concept_count AS BIGINT) * CAST(concept_count AS BIGINT)) AS squared_concept_count
FROM concept_count_data
GROUP BY cohort_definition_id
)
SELECT
t1.cohort_definition_id,
CASE WHEN t2.cnt = t1.cnt THEN t2.min_concept_count ELSE 0 END AS min_value,
t2.max_concept_count AS max_value,
CAST(t2.sum_concept_count / (1.0 * t1.cnt) AS NUMERIC) AS average_value,
CAST(CASE
WHEN t2.cnt = 1 THEN 0
ELSE SQRT((1.0 * t2.cnt*t2.squared_concept_count - 1.0 * t2.sum_concept_count*t2.sum_concept_count) / (1.0 * t2.cnt*(1.0 * t2.cnt - 1)))
END AS NUMERIC) AS standard_deviation,
t2.cnt AS count_value,
t1.cnt - t2.cnt AS
Caused by: org.postgresql.util.PSQLException: ERROR: column “temp.cohort_definition_id” must appear in the GROUP BY clause or be used in an aggregate function.