All, CDM v6.0 was release over two years ago and it seems like we are still at a low rate of adoption. One of the main drivers is the fact that the tools we all use to define our cohorts and run our studies do not yet support this version. For the record this is not meant to shame our wonderful developers. They have been working extremely hard to add new features to ATLAS, CohortMethod, PatientLevelPrediction, etc. This is simply meant to point out that something needs to be done to help move v6.0 forward. I spoke with @schuemie along with the other members of the HADES workgroup to understand what we can do as a community to increase support of this CDM version.
As a reminder one of the biggest changes between v5.3.1 -> v6.0 made all *_DATE values optional and all *_DATETIME values required. This was part 2 of a three-part effort to eventually remove the date values in favor of the datetime. As Martijn pointed out, many data partners do not have data with the precision of time information so time must be imputed. The current convention is to set the time at midnight (00:00:00) if time is unknown. This then presents a problem: how do we know when times are assigned the value of midnight vs when an event actually occurred at midnight? This question seems to be the biggest barrier to wider adoption and I talked through some solutions both with the HADES group and the CDM working group. I am eager to have the community weigh in on this so please read through the options and comment/discuss below.
Add a precision column for each datetime value With this option we would continue on our path to eventual deprecation of the dates and add a precision column for each datetime indicating the lowest level of information given in the source data (day, hour, minute, second). This would mean that we would need to think about how the precision would impact our current coding practices, however, both @msuchard and @hripcsa mentioned the use of a datetime precision column in other projects and this seems to be the way many other groups are handling this sort of uncertainty.
Revert *_DATE fields back to required for now This option is the lowest barrier to entry to get the current tools working on v6.0. The plan as discussed in the CDM workgroup meeting would be to revert the requirements for now to allow for our backlog to catch up. Many people have been waiting for the oncology tables, bugfixes, and updates and this would give us the time to do that while still allowing use of the tools as-is.
Some combination of 1 and 2 This option would be to start with #2 as a way to clear out our backlog. We would write up a formal proposal for #1 and go through the proper process to get it approved. The idea here is to give everyone some time to work up to #1 as we are not clear on the amount of rework that is necessary with such an implementation.
We are interested in your feedback, this decision of course affects everyone and we in the CDM workgroup want to make sure we take everyone’s thoughts into account before settling on a decision.
After reading @clairblacketer’s post, I wondered if it would be helpful to reframe the problem statement slightly.
I could be mistaken, but I thought OHDSI was advocating the convention of using a time of exactly midnight (HH:MM:SS = 00:00:00) where time is missing in the source, and shifting actual midnight events by one second to 00:00:01. I am skeptical that introducing such an intentional “error” in one out of 86,400 seconds in a day would be a deal-breaker for any analytics use case, but I’m open to be proven wrong.
The problem statement as I thought @Christian_Reich framed it was this one: What conventions should the OHDSI tools use to calculate elapsed time or durations when one or several OMOP instances, taken individually or consolidated, may contain a mix of full datetime values and date-only values?
When we populate only date values, then this decision is easy: you can subtract one date from another to yield an integer duration in days.
One option for these tools is to continue as before, applying a CAST(), TRUNC(), or equivalent function in your database to the CDM v6.0 datetime columns. There is some debate over the database query performance implications of such a choice.
I don’t see how the proposed Option #1 solves this problem. Our tool makers would still need to decide whether to read the precision column and perform complex logic, or simply go with the much easier CAST() operation.
Replacing (by requiring one and making one optional) date field with date/time field has a number of consequences, one of them is breaking all of the code that assumes the use of dates vs. date/time. There is not easy fix for that, it is not a simple cast required.
Another thing, most of the use cases do even not require the time portion - today or in the future. There are only some that do - so why force the rest of us to do some magic to “remove” the time portion from their queries to make it work?
I think a better - and easier option - would be to use two fields:
date - for those use cases that need a date
time (or date time) - for those use case that need a time stamp and where it is actually available
now the existing tools continue to work and those that require a time portion can be built. The only side effect I see is a bit of a duplication if that will date/time. but I am wondering why we cannot just do it as a time stamp - why date time? most of the database I checked that we have today seems to support it? (and i am sure there is a lengthy forum thread on this already exist somewhere )
@gregk proposed a reasonable alternative. But ‘datetime’ column (rather than ‘time’) makes it easier to find ‘prior’ events to the index datetime. Since we need to support various database system, ‘datetime’ can be safer than ‘time’ column (even though it’ll be so redundant… )
I think there’s a more fundamental problem: irrespective of how the data are stored, how should we use date/time information at various levels of precision?
Up till now, life was easy: all information was assumed at the date level. It was clear that you could ask “how many days are there between event A and B?”, and “does the day of event A precede the day of event B?”, but not “How many hours are there between A and B?” nor “does A precede B if both are on the same day?”
If we allow for different levels of precision this becomes much more complicated. If A and B are now at the millisecond level, there are more questions we can answer. But that means that for example a cohort definition having a criteria for an event to happen in the 10 minutes prior to index that runs on one database (having milliseconds) will need to throw an error in a database that has events at the date level. Currently cohort definitions aren’t allowed to throw errors like this.
This becomes even more complicated if we allow a database to contain multiple levels of precision (which actually happens more often than having a database all at the millisecond level). If A is at the date level, and B is at the millisecond level, if A and B are on the same day, what is the answer to the question “does A precede B?”.
I must admit I don’t have a good answer. But we can’t adopt any solution in our software until we do.
Great discussion, and great point about semantics. Some options are:
a. Adopt Allen’s Interval Algebra as OHDSI’s semantics, where the interval is the possible time the event may have occurred (dictated by the granularity). There are 13 operations that cover all the possibilities in comparing two intervals. I believe it would be too complicated and never catch on.
b. Develop a simpler algebra that basically answers yes, no, or maybe for every temporal question and asks you to say whether to put maybe in yes or no for this question. I think I have this right, but could be wrong.
c. Decide to assign “maybe” to “no” for all OHDSI questions, so that “yes” means definitely yes. If you want it the other way, you just flip the question so the maybe becomes what was previously a yes. We could rename our comparison “definitely greater than” and “definitely greater than or equal to” to remind people which way the logic goes.
d. Adopt Allen’s interval algebra in some esoteric instruction manual but also create simplified operators like either (b) or (c ).
For the original question, I have a slightly different suggestion (at least I think it is a possibility, but I have not gone through it enough so feel free to point out the problems). Call it option 4.
Make timestamp (not DATE) mandatory with the stipulation that you have to get the date right and do whatever you want on the time. Modify OHDSI tools so for now they ignore the time and perform only date operations. But you can put in some suggested semantics (and maybe an optional granularity column), and you are welcome to use it for your own research, eg, in the ICU. This pushes everyone to use the timestamp column, temporarily reduces the work to get the tools running (I think because all the date queries have to get truncated to date but we don’t have to change the user interfaces) and reduces training, but begins to support ICU and similar research. The down side is that the OHDSI tools would have to be changed twice.
Well - we can add “precision widget” to all events. (or not and think about other options)
But to Martijn post - we can ALSO put “precision widget” on cohort criteria.
So when you author anything temporal for Atlas cohort, you first choose a precision regime and than you can author and we will support just some regimes (in early versions).
One of my pursuits is genealogy. They hav a solution for imprecise dates that are very common in genealogy. It’s not uncommon for someone to appear in a record in, for example, 1920 and then be listed as a previously deceased husband in the widow’s 1940 obituary. So the husband died ≬1920/1940. I use, in my coding, the Unicode math symbol ≬ (between; decimal 8812; hex 226C).
The genealogy standards are GEDCOM 5.5 or GEDCOMx. I still use the older GEDCOM5.5 because I have legacy code: it uses one of modifiers ABT (about), BTW (between), BEF (before) and AFT (after). In my data management, the table contains a date field and a date_mod field. In the later I use a symbol <,>,c,- for before, after, about (circa) and between. For the between I include the upper range value right after the -. Thus, in the example I gave the date field is 1920 and the date_mod is -1940.
If you’re building from scratch, you might find GEDCOMx more suitable.
You’ll need a few (not many) functions to do the required computations, which will also be imprecise: born about 1935; tonsillectomy when about 5 years old=about 1940. Such ambiguity is very common in medical histories. But this strategy provides an mechanism to manage it. It sounds very close to the proposal that started this thread.
Dave
David A Stumpf, MD, PhD
Professor Emeritus, Northwestern University
Woodstock, IL 60098
Date/time as required: making a field where we know ahead of time that the time information is not available in most of the cases? And then make up a convention to figure out how this field was populated, what precision exist. And then make people strip out time part in most of the queries anyway through cast or some other magic, while affecting performance and increasing complexity. This approach is probably not the best - in my humble opinion,
Date information is consistently available - whether this is claims or EHR. This is what should be made as a required field.
Time portion is important for some critical us cases, yes - but I would propose to make it optional.This way we know it is populated when it is really available (vs. made up through a business rule).
The precision - date (year and day), time stamp (hour, minute, second, millisecond). Isn’t the need for precision determined by the use cases and thus the type of data that is being used for analysis? Even if it is EHR data, I am wondering if someone would really trust that an event is manually entered into an EMR system has a real minute or even an hour precision. Or even a date - if it comes from claims? So, most likely the lower you go - e.g. minutes, seconds, milliseconds - the most likely this data is generated by some device and is more precise / trustworthy. In this case, wouldn’t it make sense to assume that by filtering the type of data used in analysis someone would already know what precision to expect from that type of a source? Why do we need a precision flag for events if we already know what events are associated with certain source and what precision we can expect there?
I propose to make date required again and time stamp optional. There are multiple benefits for that:
this will not break any existing tools and opens up a possibility to create new studies for those use cases where time is needed and available. We can finally move forward with OMOP v6 adoption…
no need to guess if an event has time stamp or not. If it is populated, it had this information.
precision - again, by relying on knowledge associated with source that generate data, we should be able to tell the precision that exist in data. At any level, year, day, hour or minute.
Would be really interesting to see us collect use cases where time stamp and various levels of precision is required. And some folks already commented here with some use cases
I’m not sure if one of the other projects that was discussed was HL7’s Clinical Quality Language (CQL). I had the chance to work with CQL at one point, and its treatment for precision-based timing is quite comprehensive. Although, it adds a lot of complexity if you already know and are confident with the precision of the data.
@clairblacketer do you have a link for the historical argument / use cases that prompted this change to *_DATE and *_DATETIME in CDM v6.0 in the first place?
There isn’t one single place. The discussion went over time, sometimes in the Forum, sometimes in the CDM Working group. Here is an example of the earlier debate.
This is a complex decision making. We have different timing precision in the data, and we have different use cases:
Daily precision: This is the 99% predominant situation both in the data and use cases. Most queries contain some kind of date arithmetic, because in observational data the timing is what links events to each other within a Person. Slowing this down is what caused @schuemie to restart this debate.
High precision (hours or minutes): Usually, only data collected from devices provide the precision, supporting use cases of acute (e.g. ICU) outcomes. Manually collected records, today the mainstay of observational data, rarely support this.
Low precision (months, years or decades): This is the realm of “history of” and survey data, and the use cases are broadly defined inclusion or exclusion criteria (“no prior cancer”). This is actively debated here.
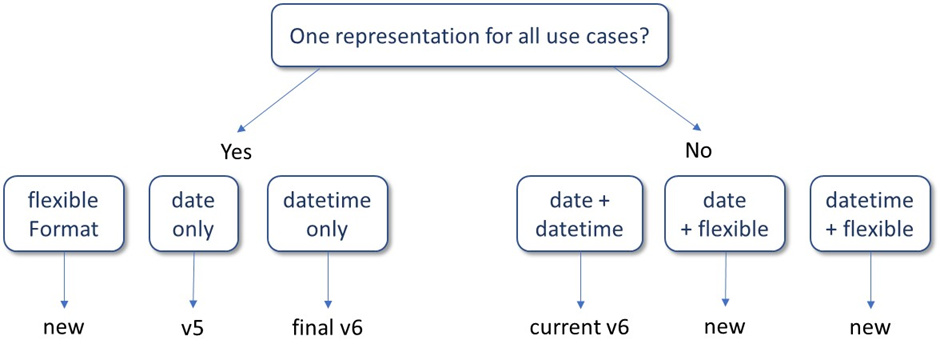
For representations, we have three choices:
Date fields, like in V5. These support daily precision only and are the fastest solution.
Datetime fields, like in V6. These support daily (albeit with a performance impact) and high precision.
String fields with flexible notation or datetime fields combined with additional precision flags, like in @hripcsa’s, @dastumpf’s and @wjmcqueen’s references to how the literature, genealogy and HL7 CQL folks solve the problem, or @clairblacketer’s solution 1. These support any precision, but are slow or very slow and the arithmetic is complicated, particularly if involving different precisions.
We therefore have 2 decisions to make: (i) do we want one way to account for timing, or do we want to split the problem into the 99% straightforward daily and the 1% exceptions, and (ii) what representation do we want to pick?
V5 only supported daily precision. When we designed v6, we opted for a common representation (mandatory datetime) covering the daily and high precision cases, with a temporary backward compatibility (optional date). The low precision cases were relegated to “history of” Observations. We certainly could go back to the drawing board.
My preference was and still is date+flexible. It’s the fastest in most of the use cases, and for the rest there seems to be prior art of how to get the atypical precision cases right.
As mentioned earlier, I’m at a loss to how our tools should handle time at different levels of precision, so the solution we likely would’ve adopt in HADES was to cast everything to dates. If that is the case, we may as well make that explicit in the data model, and have a DATE field. That being said, we don’t want to lose information, so we’d need a separate representation to maintain the actual precision in the source data. In other words, I would choose No to answer “One representation for all use cases?”. (The right branch in your diagram).
I’m on the fence between DATETIME and VARCHAR (flexible) as the second representation. VARCHAR has maximum flexibility, and we could write R libraries to implement whatever standard encoding we’d choose. But it would be slow, with no ability to index (although we could create derived fields and index those in the fly). If we have a lot of use cases where high precision is important we should go for DATETIME. But I guess we don’t (?), so that would argue for DATE+VARCHAR(flexible).
Does date + datetime leave datetime as nullable? I would prefer that to the ambiguity of using 00:00:00 as a sentinel value. Nulls have their own issues in different environments. Do we have use-cases that could be used to argue against this?
Clearly the flexibility you get from VARCHAR is also the flexibility for bad data and bugs, so you’d want to specify carefully and add rules to DQD. It should be an informed decision to decide against the established (tested, debugged) code and type safety or data quality you get with DATETIME. Having said that, while adding DATETIME makes progress regarding date vs time precision, it does nothing to distinguish data accurate to the hour from data that is accurate to the second or millisecond.
How and where do you store the precision data? This goes back to the question of whether precision should be recorded together with a value. There is a bit of this when you use 00:00:00 as a sentinel value for not having a time value where you may not know if all zeroes is meant as exactly midnight or the sentinel value. If we use DATETIME and have separate metadata for precision, you can exploit things like the unit field in BigQuery’s timestamp_diff function, while keeping useful aspects of DATETIME.
 )
)