Hello OHDSI Community!
@Ajit_Londhe
Why might cohort generation show too few records for certain datasets even though the Dashboard reports are accurate?
We have two data sources set up in ATLAS:
- The initial dataset set up along with the Broadsea installation (ATLAS + WebAPI version 2.10.0), which is in the same database as the WebAPI schema.
- A newer version of source 1 that has been updated with additional records, which exists in a separate database.
When we create cohorts in ATLAS, source 1 displays the same or nearly the same number of records as a database query, but source 2 returns only about a fourth of the total records. The Dashboard report in “Data Sources” displays the correct number of records for both sources.
Example:
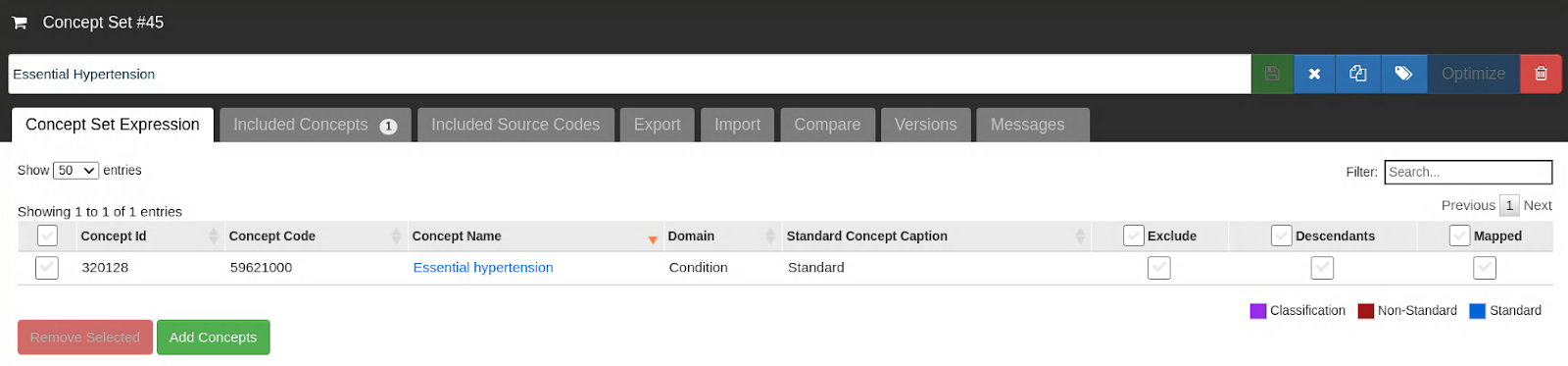
We created a concept set on ATLAS using the single concept, “Essential Hypertension” (Concept ID: 320128) and made a cohort with this condition occurrence as its initial entry event. We included all events, with no other inclusion criteria or definition changes from the default. We generated reports in the “Generation” tab and compared the record counts to a database query: select count(distinct person_id) from cdm.condition_occurrence where condition_concept_id = 320128. The number of records reported for source 1 matched the query, but not for source 2.
Can you run the SQL query from the cohort definition’s export tab against both sources to confirm? You’ll need to substitute all parameters with the appropriate schema names.
Running the exported query against the databases gives the same record counts that ATLAS reports. In both cases, the record counts are about a fourth of the total qualifying events. But there are about 4 or 5 times as many qualifying events in the old dataset, even though it is smaller than the new. For all the concepts we checked, the relative frequencies matched, but they don’t correlate with the number of qualifying events.
Hmm. Are you sure that the configuration is set up correctly, in that the new source’s daimons are not the same as the old source’s?
I believe so. Each webapi.source_daimon statement includes a unique source_daimon_id, and all the reports in the “Data Sources” tabs appear to match the data.
And the schemas in those daimons are wholly distinct?
The vocabulary is inside the CDM schema, so daimon types 0 and 1 share the same schema for each database. The daimon configurations for both tables are identical, other than the IDs which are unique, but since the server settings for each source are different, there should be no overlaps.database.
This issue might just be something on our part, either with the data or our cohort generation. We’ll take some time to look over the exported query, since it involves the OBSERVATION_PERIOD table as well as CONDITION_OCCURRENCE, and end dates might have been imputed differently in our old data.
Thanks very much for your time and help!
Just to add some ideas:
Since you exported the query and your query results match the Atlas UI (whew) you can then run parts of the exported query to understand where the differences are on the different databases.
In my experience, how Observation Periods are defined leads to differences in results. You’ll find in the ‘primary events’ part of the query (this is the part that defines the entry events), we do a join to observation_period because you can’t enter a cohort outside of observation periods. You should be able to figure out fairly quickly if your concept sets resolved to different concepts (check the concept set temp table to see if there’s a diff) and if your entry events are being pruned different between the datbases.
1 Like
we do a join to observation_period because you can’t enter a cohort outside of observation periods
Thanks, this explanation is helpful. The root issue in our new data source was that many Persons had no entry in the Observation Period table, so they were excluded from any cohort.
We finally tracked down the cause of the problem.
For background, we don’t have access to the original database, but instead we receive periodic N3C extracts from a partner organization, so we run OHDSI Atlas against these extracts. Additionally, the database contains no end dates for any ongoing observation periods, so we set these to the extract date as part of our own load script.
We didn’t realize that N3C updated its extract script in April 2022. The new filter keeps only those observations with a start or stop date in 2018 or later. Since our data lacked end dates, only start dates were considered, so all observation periods starting before 2018 were absent in the newer extracts.