This may be a topic for the CDM WG but I’d like to get a discussion rolling about “Annotation” in the CDM. To clarify what I mean by annotation (and how it differs from the metadata and fact_relationship tables) , I’ll provide a few example annotation scenarios:
I am doing a manual chart review and want to annotate something about a particular patient that is 1) not precisely temporal 2) not easily represented by a concept (unresectable head and neck cancer that has failed 2 cycles of drug X and reviewer confidence is 8 on a scale of 1-10 that this is correct). This is not intended to be a cohort definition but rather an annotation about a particular patient.
I want to highlight something about a time period that might affect multiple patients. For example, Hurricane Harvey likely affected medication compliance in a set of zip codes over a period of time. How can I annotate the CDM wth such things that are not exactly traditional metadata.
I’m sure others have examples and I would like to hear about them.
At Georgia Tech, we have have been dealing the both of the above. The most pressing need for us is annotation related to chart review. As a placeholder, we have developed an initial data model for defining annotation sets and answers in JSON. I think we should work as a community to achieve a consensus on how to approach this type of thing (if people are interested).
We can move this to GitHub or take up with the architecture WG etc, but just wanted to get the ball rolling.
This touches on a general theme of data provenance, and how that can be captured with meta data. This is generally more important when site comparisons are made, as OHDSI can catalyze.
For instance - while this might not effect CDM data directly - in the administrative data world, different countries have different rules about, for instance, what should be the primary diagnosis for a visit. In the US, it’s the admitting diagnosis, in Canada, it’s the diagnosis that consumed the most hospital resources.
(So in the US a Hip Fracture case that gets a post op MI would be primary Dx of Hip Fracture, in Canada, Primary Dx of MI).
There may also be opportunities to provide better information as to data element provenance. Is it relevant that a source concept originated as a billing diagnostic code vs. a professionally abstracted diagnostic code - typically yes! I am still digging into the CDM but not clear how that kind of provenance info is captured.
Further downstream, I think there’s some interesting opportunities to connect to source data architecture - i.e. how the data is captured in EMR systems. In our current EMR project, we’re working with / consuming large numbers of archetypes from OpenEHR https://www.openehr.org
(search, for example, for their laboratory archetype. This offers a glimpse at potential metadata slots in a Lab result, but also potentially a Lab order).
I think the combination of an Open clinical data architecture system, with analytics driven by the Open CDM, is really attractive. Perhaps of some relevance to the metadata discussion.
@bnhamlin can this help meet chart abstraction done for quality measures? E.g. if a quality measure requires hba1c every three months, and this lab was done at the point of care be provider and results typed into EMR notes - can annotations with reference be considered equivalent to chart abstraction
I would be very much interested in participating. I have worked on chart abstraction systems and having a canonical, blessed OMOP annotation format would be great. Might be good to involve the NLP working group as well, as much annotation is confirmation/revision of NLP output over clinical narratives.
I am currently looking to ways that we might allow NLP to enhance our non-standard data assignment. CDM is the only way we will achieve this and I would be very interested in pursuing this in a practical measurement context to see if there are best practices that could be built into the existing HEDIS ECDS data rules. The more guidance we can provide HEDIS auditors on standardized assessment of data provenance, the more likely it will be approved for future use.
I absolutely agree with @mgurley and @bnhamlin that the NLP folks will have a lot to add to this discussion. In a sense, the approach taken in the term_modifiers field of the NOTE_NLP table represents this need to have complex characterization of something (in this case, a term) be persisted along with the nlp_system whence this information was derived.
Similarly, we have a set of systems (human or otherwise) that generate annotations that we might want to persist. I think OHDSI being OHDSI, we should have the expectation that the format of each system’s annotation(s) be specified up front and stored in an e.g. annotation_definition table. Then the annotations could reference a source system and, even if the annotation value is just a blob of JSON, it can be understood and utilized by others.
I worry a bit about a Calvinball type situation where we come up with a million ways of annotating the same information. So as usual some community conventions would need to tighten up how we want to capture, for example, a chart review. But there would be enough flexibility to add new annotation systems independently and converge over time.
@Christian_Reich - a question is whether this is really a CDM level issue or more appropriate as part of the OHDSI result schema, being generated by various OHDSI applications.
In any case, spitballing here for feedback…
ANNOTATION_SYSTEM
Annotation System (version etc)
Annotation System Descriptor
Annotation Target Type (the type of thing that is annotated ENUM dataset, patient, period, concept, etc)
Annotation Target_Format (JSON blob providing format of how to specify the thing being annotated)
Annotation_Result_Format (JSON blob providing format in which the annotation results will come)
then I guess just…
ANNOTATION
Annotation System Id
Annotation_Target (JSON)
Annotation_Result (JSON)
Date_Updated
I have always liked how some stock market financial charts will show the price time series with annotations about news events relevant to the company overlaid on the chart. I could see annotations taking that form for us as well. Imagine looking at a trend line for the use of a particular drug and having annotations that describe when a major publication took place, or the introduction of a black box warning.
I would like an annotation system that supported “discovering” annotations that might be relevant as well as direct annotations. By “direct annotation” I mean something like an annotation on a person’s profile, where the person_id is the identify by which you would discover the annotation. Whereas “discovering” an annotation might occur if you are looking at measurements for a particular person and we have information that tells us that the underlying CDM lost access to a Quest diagnostics feed during the period of time we are evaluating. In that case the annotation might be on the measurement domain for a limited time period.
Copying my post from “Social media data in the OMOP CDM,” @jon_duke suggested that social media data could be used as a good use case for annotations. “i.e., you may not have per person social media data but there may be trends in social media occurring over periods of time or in regards to a given set of concepts etc.”
Has anyone considered incorporating social media data into the OMOP
CDM? I saw this notice from the FDA on mining social media for adverse
event surveillance:
This is a very interesting topic that I’ve been working on a bit the last few months, although with different use cases in mind. The metadata and annotations poster I presented at last year’s Symposium, along with the Atlas software demo presentation I gave in a December community call defined “metadata” and “annotation” as follows:
Metadata is simply observable information about CDM data. It can range from purely informational, devoid of any practical utility to highly critical information that could affect the validity of analyses. It could be machine- or human-authored. A simple example I showed in the community call demonstrated how Achilles Heel results could be stored in Metadata. Or, maybe a loss in death data observed in Achilles results could be tagged.
Annotations are human-authored notes about that metadata that can offer suggestions or workarounds to aid analysts in avoiding poor study design. Back to the Achilles Heel example, I demonstrated that Heel annotations from ETL owners could be stored here (e.g. “Not an issue, due to X”). For the death data loss example, a suggestion from a data source subject matter expert about how to choose study windows that don’t include this sudden shift in death data could be stored here as well.
From the discussion in this thread, it sounds like aside from tagging and annotating data source anomalies or data source characteristics, you’d like to focus on tagging patients based on clinical observations that may not need to be temporally or conceptually constructed.
Could we could combine these efforts into a singular metadata strategy?
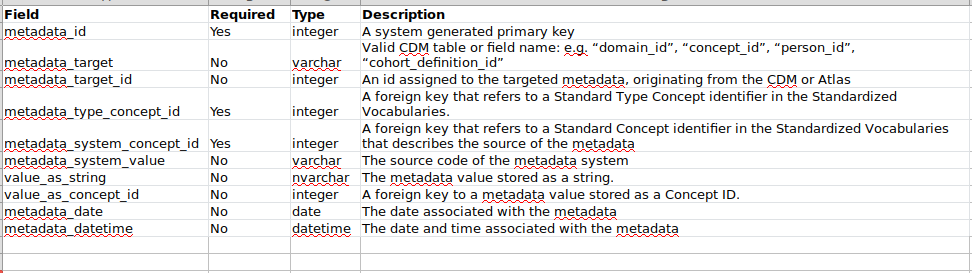
Currently, we have a Metadata spec in v5.3: Home · OHDSI/CommonDataModel Wiki · GitHub, and a theoretical Annotations table (in the infamous localhost), but unfortunately, these don’t lend themselves well to storing patient- or cohort-level information. Perhaps, we could integrate the idea of a “target type” as Jon suggested, as well as information about the originating source of the metadata and authorship of the annotation.
With the tables below, you could have a few clinicians annotate the same patient (and, optionally, a specific concept_id experienced by that patient on a specific date). You could also tag and annotate data existing at a table, domain, or concept level.
Using your table structures above, let’s say I want to point out that a particular drug received a black box warning from the FDA on 1/1/2015. Am I correct that I would say:
in metadata:
metadata_id = 100
metadata_target = DRUG
metadata_target_id = (some drug concept id)
meatadata_date = 1/1/2015
then in annotation:
metadata_id = 100
value_as_string = “black box warning from the fda. read full article here: http://www.fda.gov/stuff”
valid_start_date = 1/1/2015
Elsewhere, FDA adding a warning to a product label is not a vocabulary
construct. The fact that a product label contains an adverse event in the
warning section for a particular label is something that should be stored
in the LAERTES/CommonEvidenceModel, and should be pulled from SPLICER once
that’s all cleaned up. But the change to the label itself, I’d suggest we
need to think of them as ‘annotation events’, which are time-stamped
observations, which could then have relationships to other entities, such
as the drug or outcome associated with it.
Agree with Patrick. We don’t create vocabularies like that, even if we were to answer yes to that question: We have no capacity to be a vocab holder where we have to curate potentially thousands of entries. But we are also saying no. LAERTES should be the source of that knowledge.