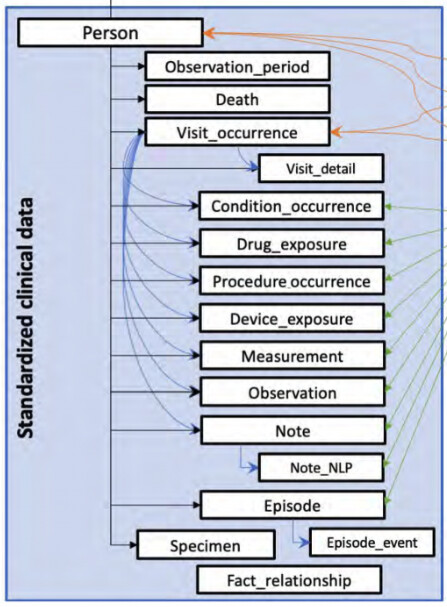
I have been working on a project where we’ve been attempting to make the most flexible source data to OMOP CDM conversion possible. That has proven very difficult, if not impossible.
One part I think works somewhat well is that to map our source data to standard concepts we have implemented a word embedding search. We did this by creating embeddings of the text in Athena and then we find the closest matches using the FAISS method. We initially used cosine-similarity, but that did not scale well at all and we have had very similar results using the FAISS method with much greater performance.
Ok, now let’s say that I have all my source tables/columns and my data mapped out to standard concepts. What would be the next best step? I’m having a lot of difficulty creating SQL statements from the mapped data to satisfy the OMOP tables/columns.
For example, let’s say I have birthdate as a source column in the patients table. I can find this concept ID using the embedding comparison that we have. Athena This shows that it goes to the observation table which I guess makes sense. but we also need to create the person OMOP table as well with this. I’m guessing we would need to create a process that watches for these codes to create the person table? Also, how do you handle the column names inside the tables like observation? Athena doesn’t seem to provide any information in that regard. Where would I place the birthdate value in observation?
I’m at a loss to do this programmatically. I’ve been looking at Perseus and Usagi to maybe help out in this step.
Looks like you overshot your goal by far. For all coded data (like ICD10, CPT4 etc.) the mappings exist in the Standardized Vocabularies you can obtain from Athena. For free-text or in-house codes you would have to do that using Usagi, but that is not typical. Demographics, provider information, visits and the likes you have to do a proper ETL, that’s not coded stuff.
But everything is described in the Book of OHDSI, especially the ETL chapter. Good luck.
Forgive my lack of OMOP knowledge for it’s about to show. It’s has been very overwhelming and difficult for me to grasp.
The source data we have is pretty much all what I think you would consider free-text. These are survey questions that are made up/free-written and given to patients to fill out.
Our first step to convert this data to OMOP CDM, was to attempt to map these to questions and answers to standard concepts. The first issue with our data is that text similarity/comparison didn’t work that well in finding relevant concept ids and was labor intensive given all the data and having to manually search for matching concept ids. This is why we leaned on using word embeddings comparisons instead which is more of a semantic search comparison. And It seemed to work fairly well in the small tests I have done.
Now, it seems that having to write out the entire ETL for every OMOP table/column isn’t a viable approach given that the source data has been mapped to standard concept ids, and that I might be overlooking an OMOP tool that already exists for this? Hopefully anyways! Is it possible I can leverage Usagi and use my mapped data and carry out the ETL? Per the ETL chapter, it does seem like the entire ETL process is completely up to us to write out? I suppose that makes sense given that the actual data values can vary a lot. For example, in our data Male and Female in our data might be represented with 0, and 1. Where in the ETL chapter, I see the example logic might be represented with M and F. I can understand that part of the ETL. What I don’t really understand is if we are to then carry out the logic with creating the each of the entire SQL INSERT statements for the person table and so forth for all the other OMOP tables/columns.
Am I expecting too much and/or misunderstanding the meaning of mapping standard concept ids?
You start with the person record, it isn’t typically created as a by-product of loading an observation. EHRs have patients with MRNs and insurance databases have clients with subscriber numbers or other identifiers. Each Person record is populated with the demographics and other info about the person (e.g. birthdate). Data describing the person never goes in “columns in the Observation table”.
Once you have Persons, then you process the things that happened to them and create, in your case, Observation records that link to the person. (Potentially with Visit records as well; I’m not actually sure whether they are required by OMOP conventions)
It’s true that OMOP CDM builder is essentially on their own to create ETL, although with help from what are collectively called “the rabbit tools” (including usagi). That is for two reasons:
EHR vendors consider their database structures to be IP and prohibit public sharing of their details
Every installation of even the same vendor’s EHR embodies thousands of choices about how to collect and represent various data elements so a universal ETL is not currently possible.

 Is it possible I can leverage Usagi and use my mapped data and carry out the ETL? Per the ETL chapter, it does seem like the entire ETL process is completely up to us to write out? I suppose that makes sense given that the actual data values can vary a lot. For example, in our data Male and Female in our data might be represented with 0, and 1. Where in the ETL chapter, I see the example logic might be represented with M and F. I can understand that part of the ETL. What I don’t really understand is if we are to then carry out the logic with creating the each of the entire SQL INSERT statements for the person table and so forth for all the other OMOP tables/columns.
Is it possible I can leverage Usagi and use my mapped data and carry out the ETL? Per the ETL chapter, it does seem like the entire ETL process is completely up to us to write out? I suppose that makes sense given that the actual data values can vary a lot. For example, in our data Male and Female in our data might be represented with 0, and 1. Where in the ETL chapter, I see the example logic might be represented with M and F. I can understand that part of the ETL. What I don’t really understand is if we are to then carry out the logic with creating the each of the entire SQL INSERT statements for the person table and so forth for all the other OMOP tables/columns.