I have added a v5.2 CDM dataset to the Redshift cluster set up for us by the deployment of the OHDSI on AWS environment, but so far I am unable to access the data in ATLAS. It is my understanding that I need to follow the WebAPI CDM configuration instructions at https://github.com/OHDSI/WebAPI/wiki/CDM-Configuration in order to make ATLAS aware of the new data. So far I have followed the instructions to create the tables in the results schema by navigating to the link in http://<server:port>/WebAPI/ddl/results?dialect=<your_cdm_database_dialect>&schema=<your_results_schema>&vocabSchema=<your_vocab_schema>&tempSchema=<your_temp_schema>&initConceptHierarchy=true with the appropriate values filled in, and then running the script on the Redshift cluster.
However, I don’t understand how to perform the source and source_daimon table setup step. It says to insert some entries into the webapi.source and webapi.source_daimon tables, however I don’t see a webapi schema in the Redshift cluster. Is this database located somewhere else, and how do I access it?
I’ve also tried connecting the browser to the http://<server>:port/WebAPI/source/refresh and http://<server>:port/WebAPI/source/sources URLs (where I used the domain name for the Redshift cluster endpoint), but did not get a response from the server.
WebAPI uses its own local database for internal application data, including configuration. It’s not the same as data warehouse (Redshift, in your case) that holds CDM data. Therefore, webapi schema will be found in the former.
In the docs, this is described here, with more details about webapi schema setup for Postgres and other DBMS (supported to a lesser extent though, so Postgres is better).
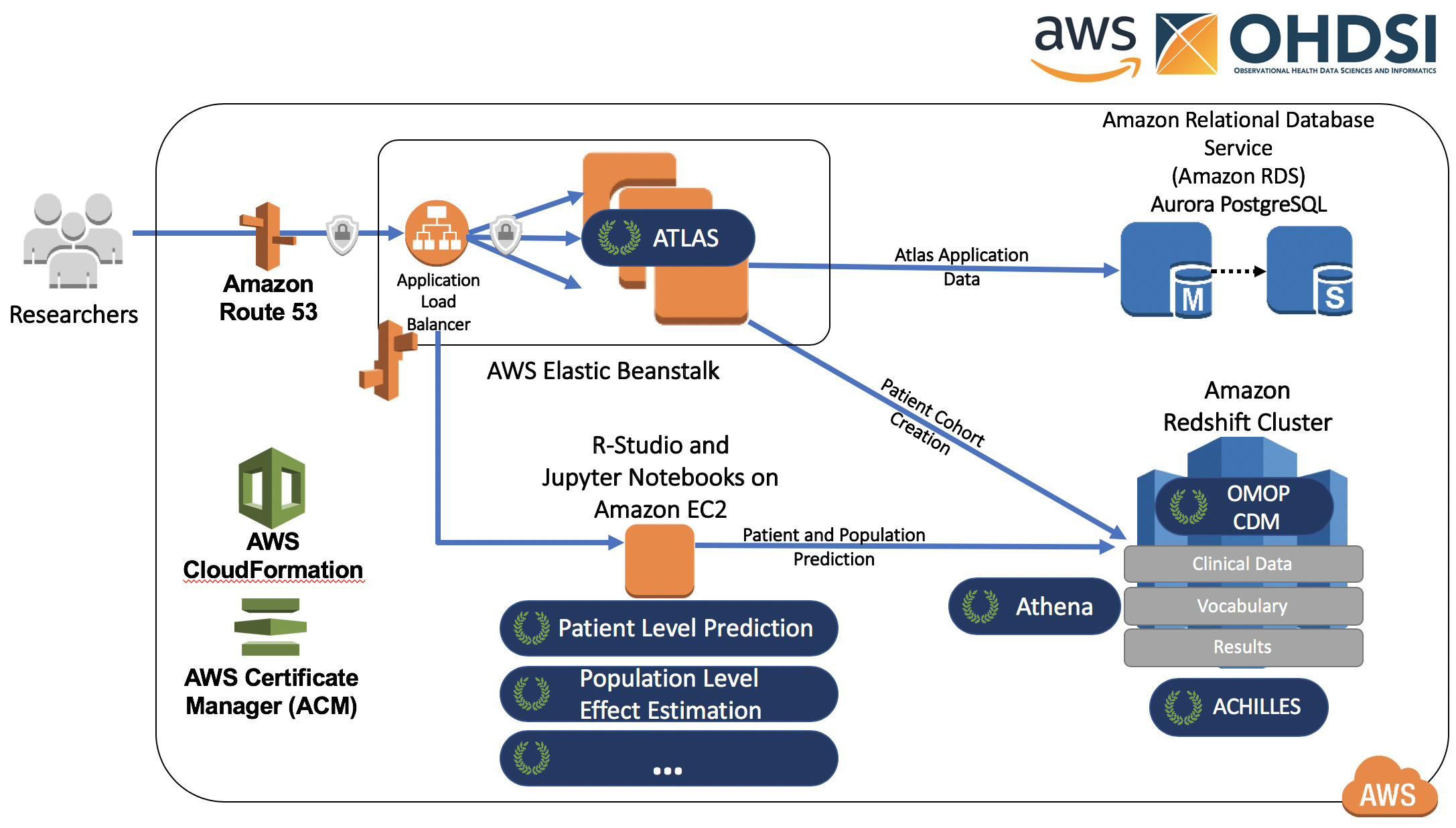
Unfortunately, the exact whereabouts of WebAPI DB in OHDSI on AWS are not clear from the repository description. You’ll be looking for Amazon RDS PostgreSQL database, which is shown in top-right corner of this diagram (from the same repo):
Also, note that in later version of Atlas it’s possible to configure new sources through the web UI, without the need to access DB directly. v2.7 is the stable one now, try upgrading WebAPI/Atlas if the stack allows it.
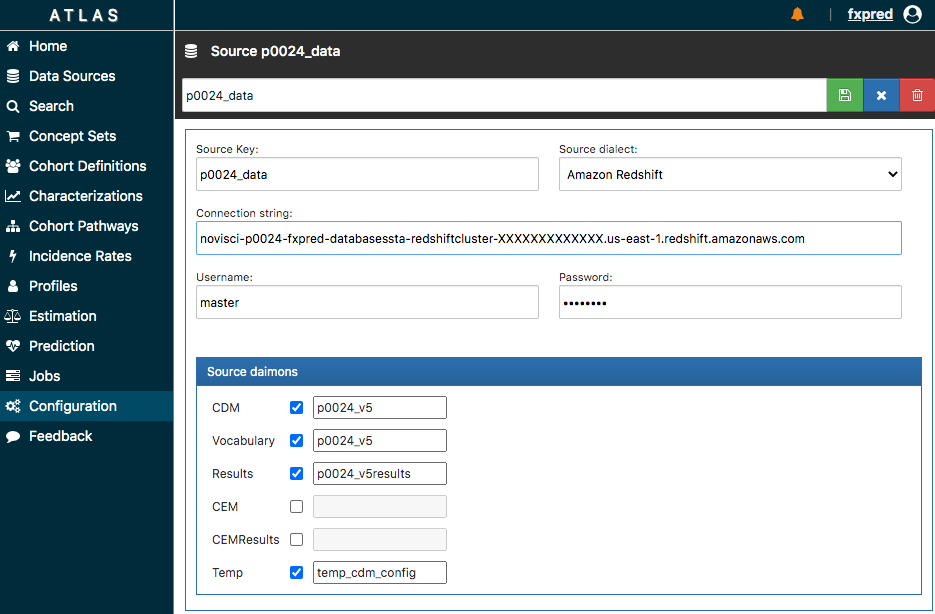
Thanks so much for this response. It turns out that the AWS stack has provided Atlas v2.7.5 for us, so I am hopeful that we can use the web UI. In Atlas, on the left-hand tab I clicked on “Configuration”, and then on a button labeled “New Source,” which brought me to the screen shown in the screenshot shown below. However, when I fill in all of the fields with my best guess of what the correct entries should be and then click on green icon of a floppy disk indicating “Save,” I get an error with the following message. Is there any documentation on filling in these fields, I haven’t been able to find any?
The Source was not saved. An exception ocurred: javax.persistence.EntityExistsException
This is what I would expect that the fields should be.
Source Key: the argument that I used for sourceName when I called Achilles::achilles in R on the data.
Source dialect: Amazon Redshift
Connection string: The Redshift endpoint
Username: the username of the Redshift superuser.
Password: the corresponding password of the Redshift superuser.
Source daimons
CDM: The name of the schema in which the CDM tables reside.
Vocabulary: The name of the schema in which the vocabulary resides.
Results: The name of the schema in which the results reside.
CEM: I’m not sure what this is, but I don’t think we have this set up?
CEMResults: I’m not sure what this is, but I don’t think we have this set up?
Temp: This is the name of a schema that is in the Redshift cluster that currently doesn’t contain any tables.
Looks like you’re one step away from success: the connection string should be not just the hostname but a JDBC connection string. So, in your case it would look like jdbc:redshift://novisci-p0024-fxpred-databasessta-redshiftcluster-XXX.us-east-1.redshift.amazonaws.com:5439/database.
I’ll just add for other people reading this thread, that if you included any of the synthetic datasets when you set up the environment, then you can look at the configurations for the synthetic datasets and copy some of the fields such as the connection string from those configurations.
could anyone help me out where this command needs to be executed if we need to create the result dataset in redshift. what should be local host and port we should be using.