The first is a percentage and the second is absolute count.
So if I have 10 persons with error in a dataset with 1k people total - the first rule will fire.
But if the dataset is large (100k) - the percentage magnitude of the problem is much smaller. (so only one of the two rules will “fire”).
A data quality problem can in absolute numbers seem big - but relative to the dataset size - it may not truly be a big problem. Size matters.
I will update the rule overview file with a better description.
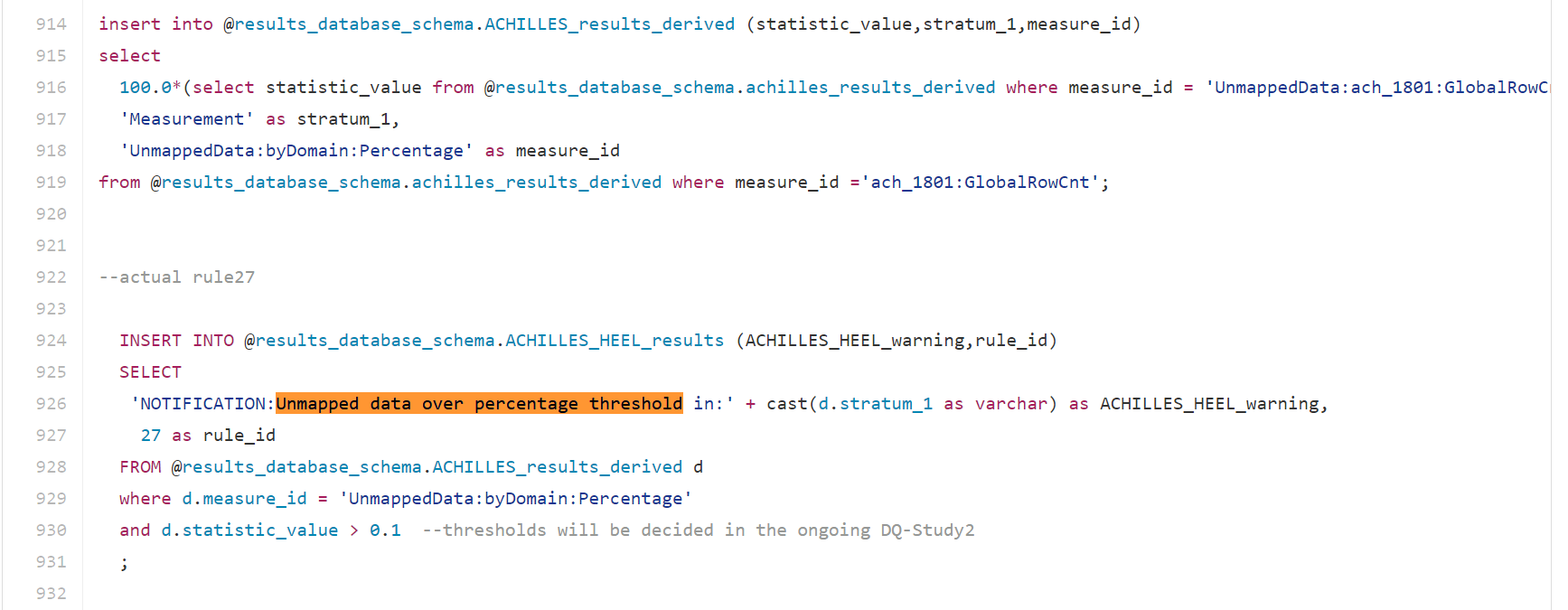
Previously - rules were not commented at all in the SQL code.
Version 1.2 introduced rule_id - so with such ID - one can go to the SQL rule file and look for the comments.
This rule can also benefit from more comments. But it is not hard to follow the logic from the SQL code.
It is using a derived measure. (Derived Measure IDs aim to convey what the measure is about.
See it here:
Also, try running
select * from achilles_results_derived
The heel result table can not accomodate ‘float’ numbers. So it can not distinguish 0.001% from 0.9 % of unmapped data.