Hello, my name is Frank DiMartini and I would like to contribute to the OHDSI community. A little background first, I am currently managing an ETL development team at IQVIA for almost a year now, with a focus on performing OMOP conversions. I have an extensive ETL background with some programming, and have been looking for ways that my skill set can contribute to the OHDSI community.
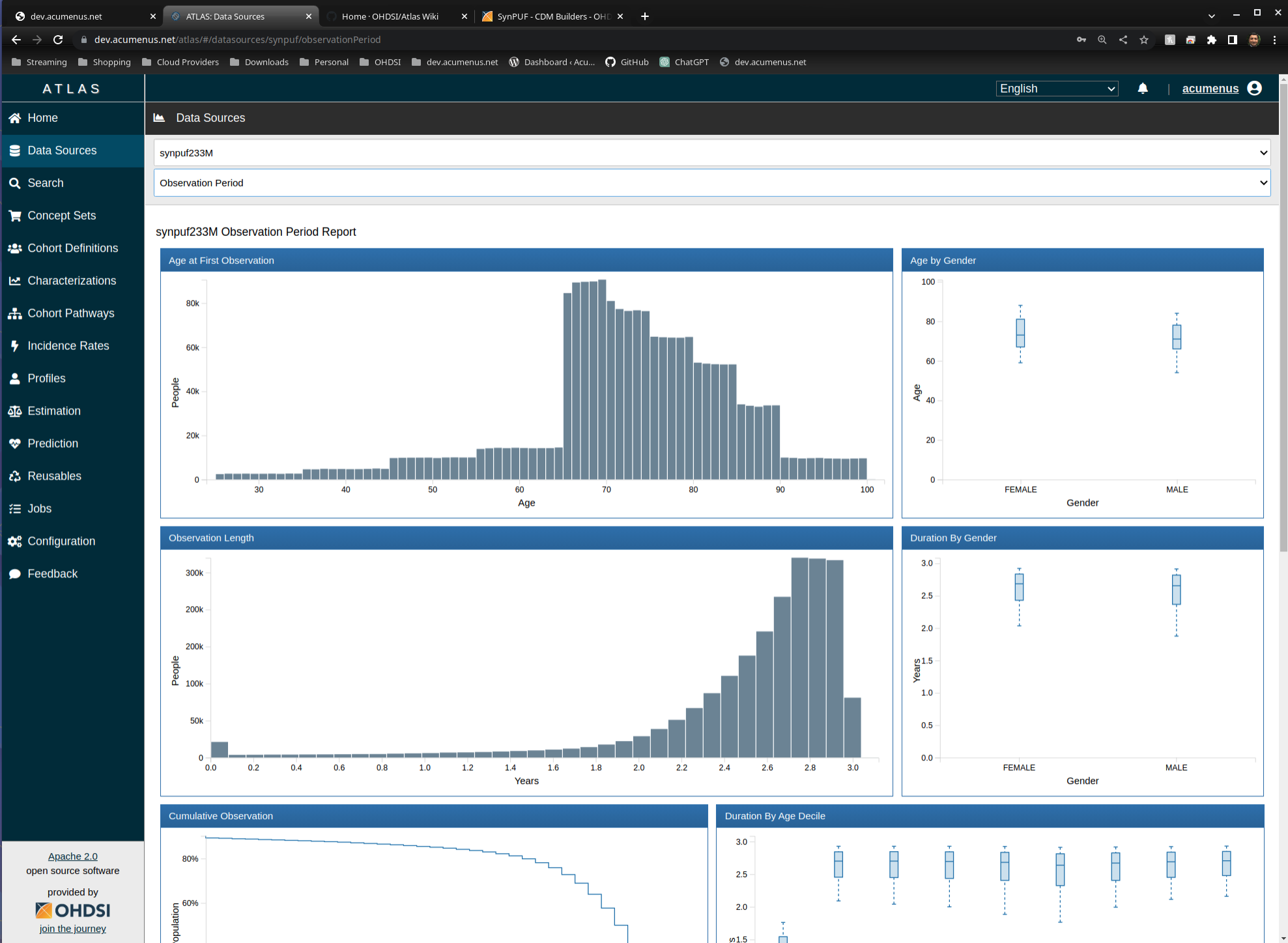
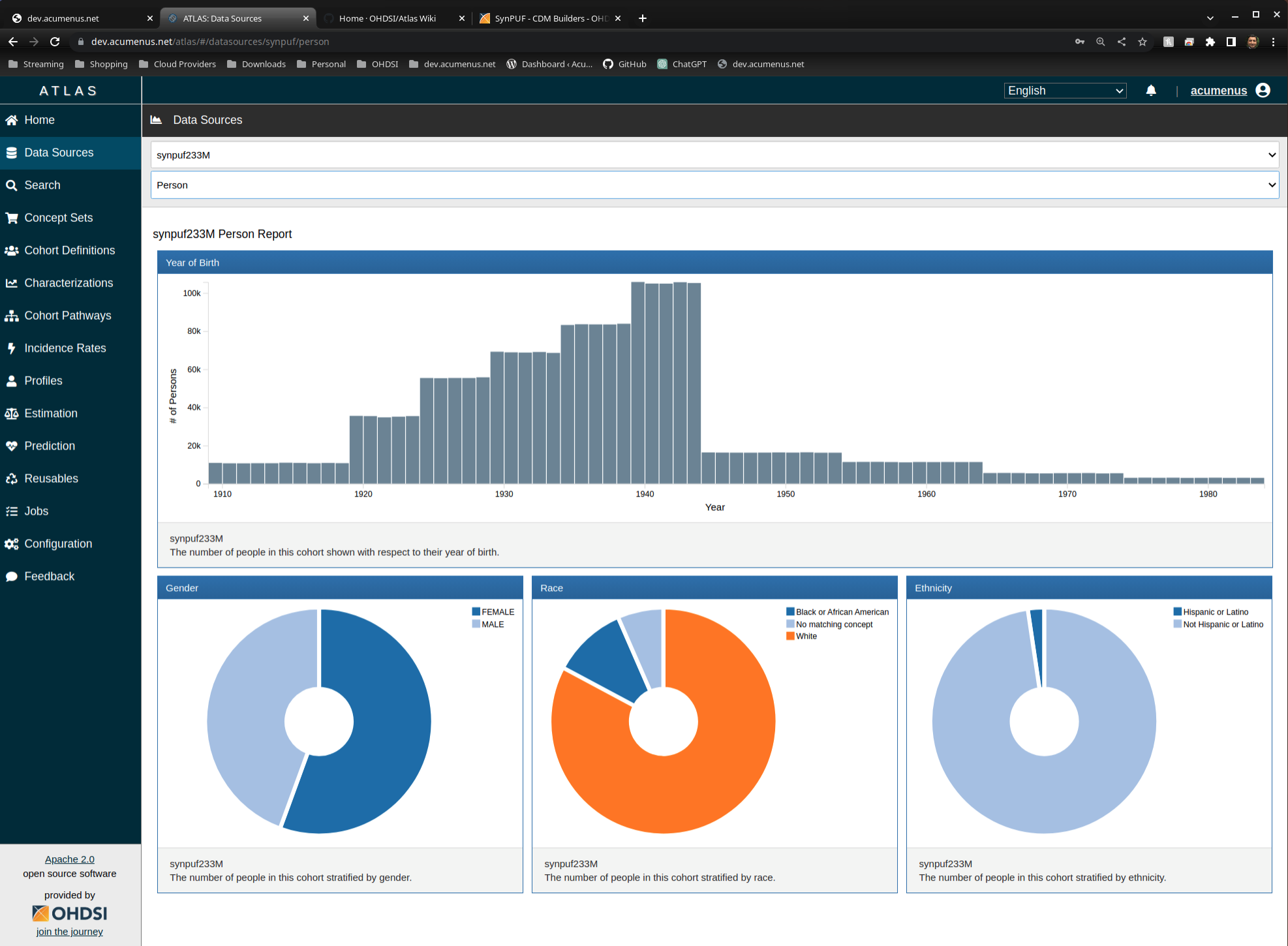
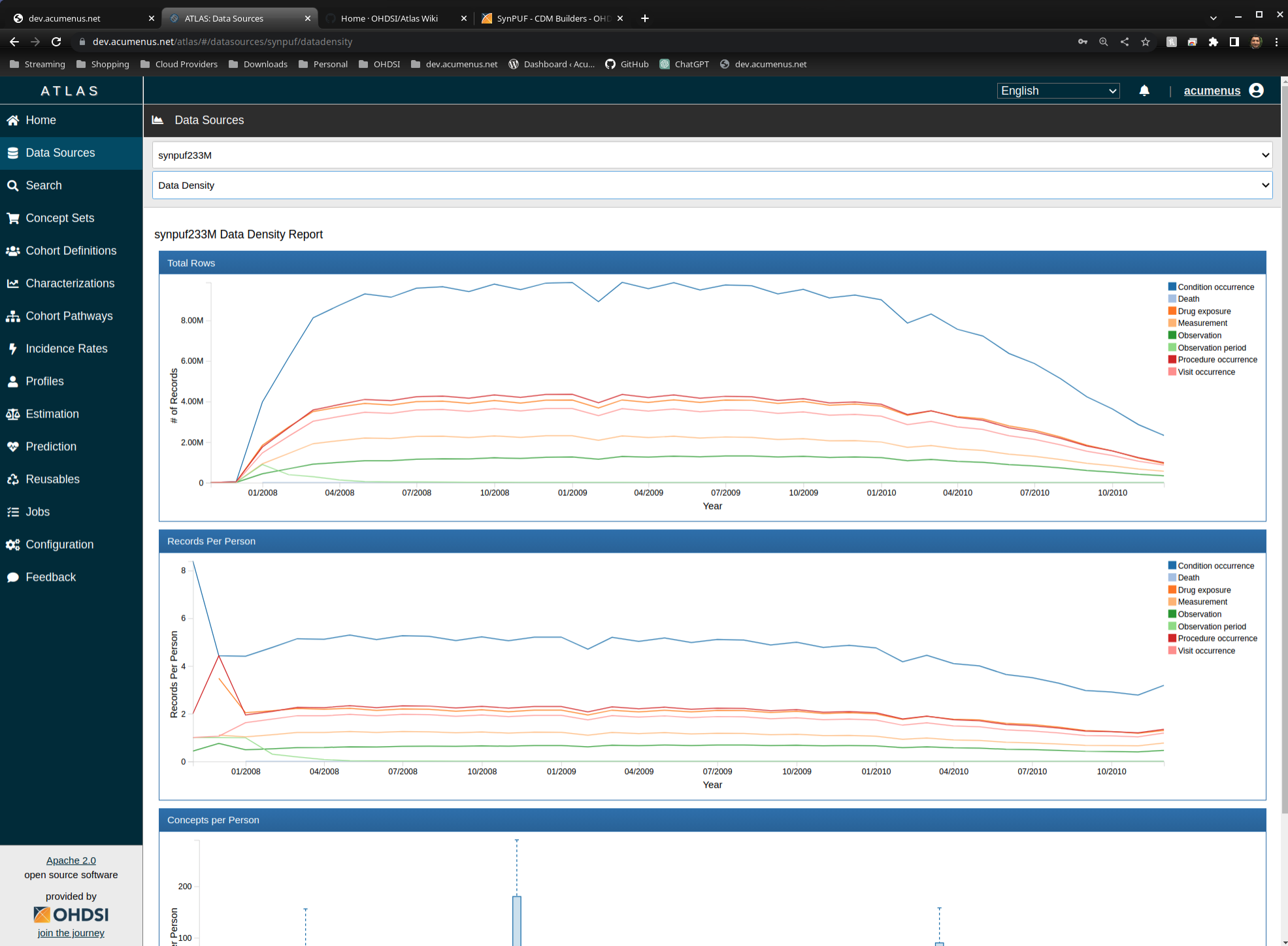
I am curious to see if there is a benefit to have scripts that load synpuf data by environment. So far, I see that there is a github page that has the DDL for a few environments (https://github.com/OHDSI/CommonDataModel) and I also see a post about loading the data via Postgres (https://github.com/mustafaascha/ubuntu-synpuf-cdm), but what I don’t see is a way someone can load synpuf data to other environments without having to create their own scripts.
So my question is, does having scripts to load the synpuf data (OMOP or source) to a variety of environments provide value to the community? If it does, are Redshift, Hadoop and SQL Server a good start? I’ll admit, those are the environments I can start with for now, but can expand later. Any feedback you can provide is greatly appreciated.