
I downloaded vocabularies from Athena and I am trying to understand the data model by studying the data in the CONCEPT.csv file.
As far as I know, the concept_id shall be “the A unique identifier for each Concept across all domains.”, but why there are duplicate concept_ids for different concept?
cat …/refer_all/CONCEPT_sort.csv | grep 73574 | awk ‘$1=“73574” {print $0}’
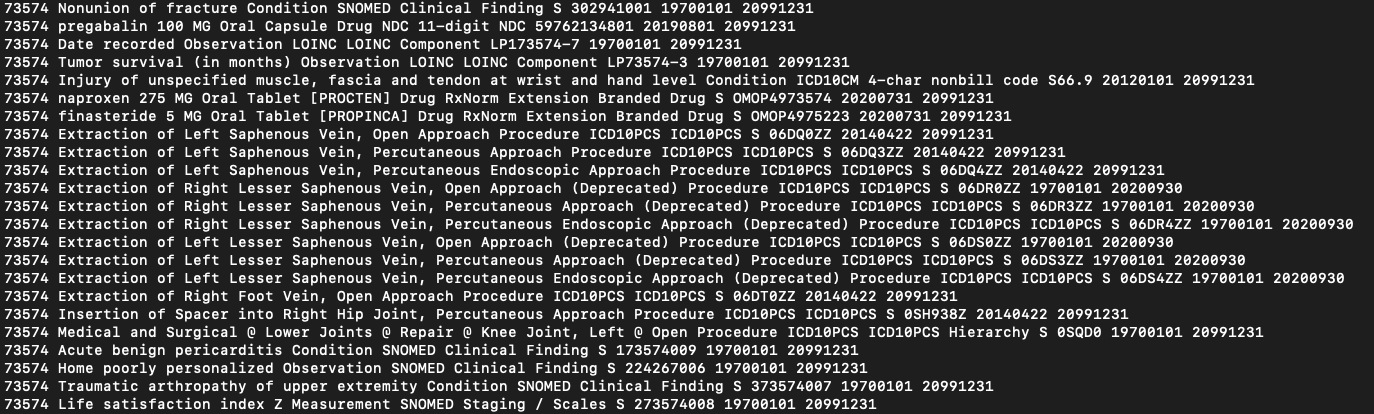
And by the way, why the csv file is not comma separated? It’s difficult to parse the data and insert into my DB.
Thanks for concerning.
