Yea I see what you mean @jposada. Maybe the renv::restore() should be executed before running the studyPackage::execute() function.
I think that we would benefit by clearly separating what an end user needs to interact with from the internals. For R study packages the user only really needs codeToRun.R and renv.lock. The StudyPackage would be installed as part of renv::restore() process but looking into the source code of the study package should not be required. Docker provides another higher level interface where users would need to pull the docker image containing the study and run an execute function in the container.
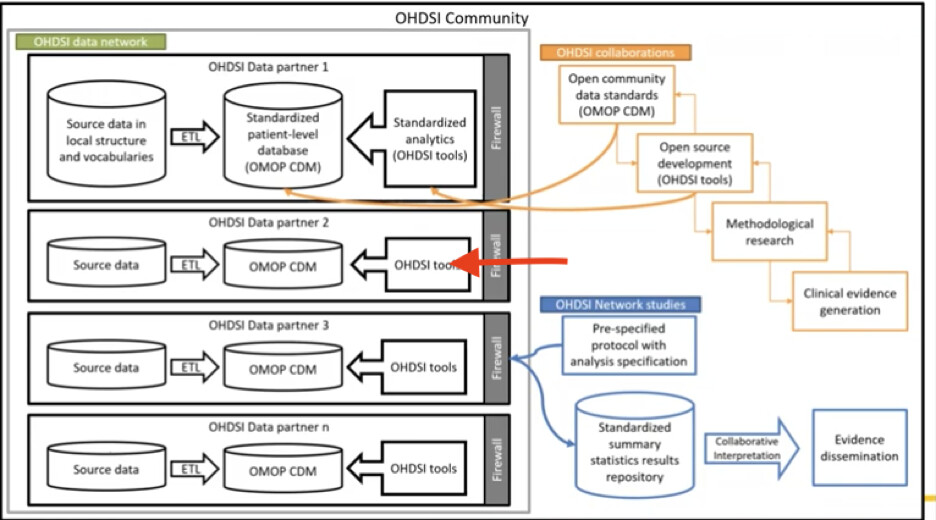
I had a great conversation with @gregk about dockerizing OHDSI studies and I think we are missing an important consideration. Consider this image that @Patrick_Ryan showed on the last community call.
The question we have to answer is “What goes through an organization’s firewall during a network study?” According to this graphic the protocol and analysis specification go through the firewall during an OHDSI Network Study. The specification is then sent to an OHDSI tool stack installed inside the firewall for execution. If by analysis specification we mean a docker image (basically a complete operating system) then we are stretching the definition of a specification.
If organizations want to use docker inside their firewall to run studies then they certainly can but sharing a docker container for every study is dangerous and won’t fly with lots of IT departments. One desirable trait of an analysis specification is that can easily pass through the firewall. As Greg pointed out earlier in this thread Arachne Execution Engine is a Docker container that is meant to be installed inside organizational firewalls and can be relied upon to contain a specific version/configuration of the OHDSI tools which can be updated at regular intervals but not necessarily on the fly (similar to updating vocabularies in ETL).
I think the important question to answer which @schuemie started discussing in the HADES workgroup is what exactly is an analysis specification in an OHDSI network study? Is our specification a complete R package along with some extra files like renv.lock and codeToRun.R?
Hey all, I think this is a really cool and important conversation! Dependency management is often overlooked. I think if we can get this right as the community grows, we will find ourselves dealing with much less growing pain!
I just wanted to add a couple of thoughts about Docker Images. I like the idea of self-contained analysis + dependencies. I worry a bit about needing to manage a store of image layers in perpetuity. Docker images, as built by Dockerfile are not reproducible. Running apt-get install inside of a Dockerfile will get the most recent version of a package at the time of run. Building a docker image twice has the ability to create two different binary images.
Luckily, (and be prepared for me to shill this a whole lot more in the OHDSI community), there is a super cool open source tool that looks to resolve this exact issue. Nix is a “package manager” specializing in “reproducible, declarative, and reliable” software builds and deployments. It is even able to replace “Dockerfiles” in a process to create docker images in a reproducible manner.
For example, here is a docker image for the OHDSI GIS project, specified in nix: https://github.com/OHDSI/GIS/blob/master/docker/loader/default.nix. It looks a lot like a Dockerfile, but is specified based on reproducible, built-from-source, functional, declarative package definitions.
I’ve been super impressed with the flexibility of Nix and am looking to leverage it in management of dependencies for the OHDSI GIS and Vocabulary projects. I think it could also be valuable for OHDSI study packages. I hope others also see the value of reproducible, side-effect free builds, and Nix becomes a useful dependency management in the OHDSI community! To anyone who is interested in experimenting with this, please feel free to reach out, I’m more than happy to teach what I know and collaborate on architecting a solution.
On the issue of HADES → Arachne Execution Engine (EE) integration, one problem with renv.lock is that it can point to a huge number of possible R packages and versions from different sources (CRAN, github, bioconductor). Arachne EE has to be able to operate in environments with limited internet access so it must be able to handle every possible renv.lock file that is sent to it which means it would need to include a whole lot of R package versions in it.
Nix sounds cool. I do think we should be careful about moving in direction of shipping software across the network instead of analysis specifications especially if our community and the number of network studies continues to grow rapidly. We might end up replacing “One study, one script” with “One study, one software application”
I agree! To be clear about my post, I wasn’t trying to advocate for shipping around virtual machines for ohdsi studies, nix just so happens to support this use case (of docker-build replacement) as a side effect.
The more important piece is shipping exact dependency lists for reproducible builds and being able to simultaneously install multiple ohdsi study packages, each potentially having a different version of the same library.
What the image is not showing is that the OHDSI tools inside the firewall are downloaded from the internet. It is software not specs which is distributed as tools. Why not distribute the entire stack as an image instead of individual R packages in CRAN? Everything inside the firewall is software that needs to come from a place. Without the software inside the firewall the specs do not work.
In summary as a community we are distributing packages and specs. Both are needed. With the level of complexity that we have with packages why not distribute all packages in a single image instead of dozens of R packages in CRAN?
A lot of studies require slight modifications of the code, and therefore a slightly different constellation of dependencies. So each study should have its own renv lock file, and in the extreme, each study should have its own image.
Fortunately, there is a subset of studies that just follow the standard approach: those are the ones that just use the study package generated by Hydra (e.g. through ATLAS). Those have fixed dependencies, although they do differ per type of study. A prediction study will have different dependencies than an estimation study, so each still has it’s own renv lock file. However, it should be possible to create an image that supports all studies in Hydra, using the code here to pre-populate the renv cache.
So if we think about sharing images instead of R packages, you could have a single image that supports only the study packages generated by Hydra, or you could have an image per study.
Some institutions prefer a set of R packages (specified in a renv.lock file), others may prefer images per study. So we should support both.
This is a great point. When the “OHDSI tools” are installed inside the firewall they go through a security review and are typically deployed on a schedule (e.g. quarterly) in close coordination with IT departments. The “OHDSI tools” can include many connected components like Atlas, Arachne EE, Broadsea, or the new GIS component that @Jake has been working on. If the interfaces of each component are well designed, documented, and tested, then they can be plugged together.
What we want from a study specification is quite different. We want something that is relatively easy for a non-programmer to review and can easily and safely pass through the firewall. The json files read by Atlas and Hydra fit this description.
I want to question the assumption that every study should require an R package developer since this is a fairly scarce resource in the community and could be a rate limiting factor in OHDSI network research. Rather than developing a package for every study we could develop packages for new study designs and once they are mature bake them into “OHDSI tools”. Would it be possible to accommodate slight modifications to studies in a specification format that could be easily reviewed by a non-programmer researcher and separate out modifications that truly require new dependencies from modifications that do not? Perhaps even better than json would be a domain specific language (DSL) for standardized analytics that is both machine and human/non-programmer readable. A few projects have been exploring this idea (Capr for cohort definition, QueryCombinators for CDM queries) Ideally this DSL code could be reviewed by a non-programmer researcher while also providing the required flexibility.
One image for all Hydra packages = Arachne EE (Documentation and renv.lock support still need work though)
One image per study = Sending around the “OHDSI tools” box during a network study; technically possible but not very secure, transparent, or amenable to non-expert use.
Yes that is true. I would argue that reviewing and image is no different than reviewing R packages. Here is a short list of services that cloud providers already offer, sometimes for free
Just to be clear: that is not what I said. Many studies require slight modifications, which is not all studies.
I would argue we already have such a DSL, and it’s called R. In my experience the level of freedom required to support all study idiosyncrasies requires a very expressive language such as R. Anything more limited will simple mean there still will be edge cases where R coding is required. Remember: DSLs are hard to learn too (maybe harder than R, which has many training resources).
It’s true that R is a DSL for statistics and data analysis. Another way to think about it is that R is a language that contains many smaller DSLs relevant to stats and data analysis. The model specification formula syntax (y ~ a + b) is one such mini language that is used by many modeling packages. ggplot2 is a DSL for creating plots. Lavaan implements a DSL for structural equation modeling. DiagrammR brings the Graphviz DOT language into R. Keras implements a language for defining neural networks. There are many more mini languages in R and each can be learned independently from the others.
One of the main benefits of using DSLs is that they expose the code to domain experts.
[From Domain Specific Languages]
R study packages seem to drive most of the evidence generation in OHDSI but they are structured more like software applications than something that is intended to be read and understood by a domain expert. By treating an analysis as a software application we are separating domain experts from the analytic code and not realizing the full benefit of R as a domain specific language for observational health data analysis.
Every other R package uses the DESCRIPTION file to state it’s dependencies so why are OHDSI R study packages different? I don’t quite understand the argument yet. renv makes sense for recording the dependencies of an analysis but I feel like we are blurring the line between the analysis code that is meant to be read by the people who design the analysis and the underlying software that implements the analysis.
I don’t think the DESCRIPTION file holds complete information about dependencies, specifically the specific version of the dependency to use. It can say something like ‘requires minimum version of 1.2’, but did you know that 2 people can run the same package with different versions of dependencies (say: 1.2.5 and 1.2.32) and the package will execute with whatever versions are installed locally.
renv makes sure a specific version of a specific dependency is loaded. It seems the standard ‘package loading’ mechanics of R doesn’t handle this at all. In fact you can’t easily go back to a particular version of a package using R: the wisdom o the R architects seem to think only in a ‘there is only going forward, not backwards’ when thinking about package versions.
So, that’s the main difference between DESCRIPTION and renv for handling dependencies. The whole point of renv was to overcome the limitations in the basic DESCRIPTION-based dependency management (and I think is a major weakness of the whole R-ecosystem).
On the topic of DSL: I don’t think DSLs really relates to dependency management, does it? If not, could we stay on topic of managing package dependencies?
I think you can specify the specific version of a dependency in the DESCRIPTION file and include packages hosted on non-cran repositories. However since you can have only 1 package version installed at a time it is better to specify a minimum version. renv does get around this by allowing multiple versions to be installed at once making it easier to satisfy exact dependency requirements. As far as I know renv is not designed to be used with R packages but maybe it works. Then we are recording dependencies twice so maybe we should to ensure the renv.lock does not conflict with the DESCRIPTION file.
It makes sense to me but I’m probably broadening the topic too much. To answer the question of how to handle dependencies we need to know what we are sending around the network during a study (i.e, a script, an R package, a docker container, any of these?). If we are sending a docker container for each study then we really don’t need to install multiple versions of the same R package (and thus don’t need renv); just put exactly what you need in the Docker container. My tangent about DSLs was an invitation to imagine sending something around the network that is readable by domain experts, maybe CodeToRead.R
I’m pretty sure it does not. That’s what I was trying to say before: the R ecosystem for dependency management is half-baked. renv seems to set up the ‘runtime environment’ of all the referenced packages, but renv doesn’t really get into which packages depend on what versions. That’s the half-baked part of renv…while the other half-baked part was the DESCRIPTION files doesn’t specify which version of a library to use, just some minimum requirements.
So, on the note of study execution: creating a prebuilt docker container is certainly one solution. Another was to use renv to restore an environment to the appropriate specification and then execute the study package. I think the docker approach puts a bit more burden on the executor (in that they need to have docker capability to execute studies, which may or may not be a low bar to enter), while renv is just another r package that you load. but renv isn’t exactly perfect either (ie: if you’re not connected to the internet to fetch the required dependency version, you get a failure) so…maybe we just support both? let people pick the option that gives them less heartache.
I will defintely support the idea of supporting the two options. If there is such thing as a base HADES image, the burden to any study-package developer is low.
Chris, you are correct - it actually can be (should be) both. Today, in ARACHNE Execution Engine we use a pre-build docker image with pre-installed set of OHDSI libraries. When study is sent, it creates a clean execution environment snapshot every time, executes, grabs the results and sends it back. Next time, it repeats. it works - and works well.
However, since it has been difficult to keep up with so many changes in that base image due to the frequent changes in OHDSI methods, as the next step to address it - we are working on making this image to be configurable, per study or organization (also configurable). Meaning, allowing admins/power user to chose a configuration as required for a study and ARACHNE EE will simply automatically create and use a configuration as specified. This would allow to lock down the configuration for that specific study across sites.
This feedback was a very nice outcome of the EHDEN ARACHNE Workshop back a few weeks ago. Would be very happy to share the latest blueprint and listen to other ideas, of course.
I also think that HADES WG should really think about releasing a core image every so often that does not change and is used across most of the studies. Maybe twice a year or quarterly? And I believe it would be great if we can synchronize HADES updates across tools - ATLAS, ARACHNE etc…
But one thing I am certainly convinced is true - it should not require a knowledge of coding or DevOps to execute a study at a data site (or in general)
This thread seems to be mixing two topics. I’ll try to provide my two cents on both:
How to handle study script dependencies
I think there’s a consensus on providing two options: renv and Docker. In general I’m supportive of that, but I’m not familiar enough with Docker (I can’t seem to run it in my organization) to know the feasibility of having a Docker container per study. Certainly having a single Docker container that supports all unmodified Hydra-generated study packages seems feasible.
Designing a study shouldn’t require R skills
We have an editor in ATLAS that allows one to design and implement studies without knowing a single R command. It suits many use cases, but not all. Over time, we may extend what the editor support (having more developers would help speed that up), but I believe it is impossible to have a generic editor that covers all eventualities.
Many studies require something more than the ATLAS editor supports, and luckily we have R, which is very expressive, to catch these cases. That does require knowledge of R, which I don’t think is an unrealistic expectation of data scientists (Google for ‘data scientist skills’, and R will be close to the top).