@SCYou - The https://www.arachnenetwork.com website is not the OHDSI ARACHNE site (which is coming back again soon - see above) - it is an internal Odysseus demo site.
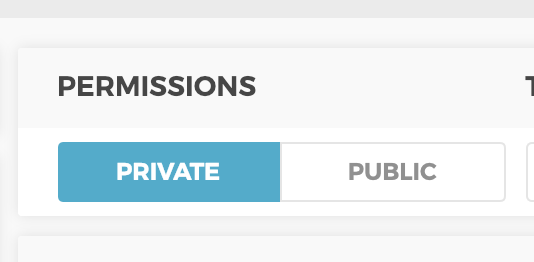
Regardless, if you would like others to see your study - create it and set the “Permissions” flag to be public (there is a flag).
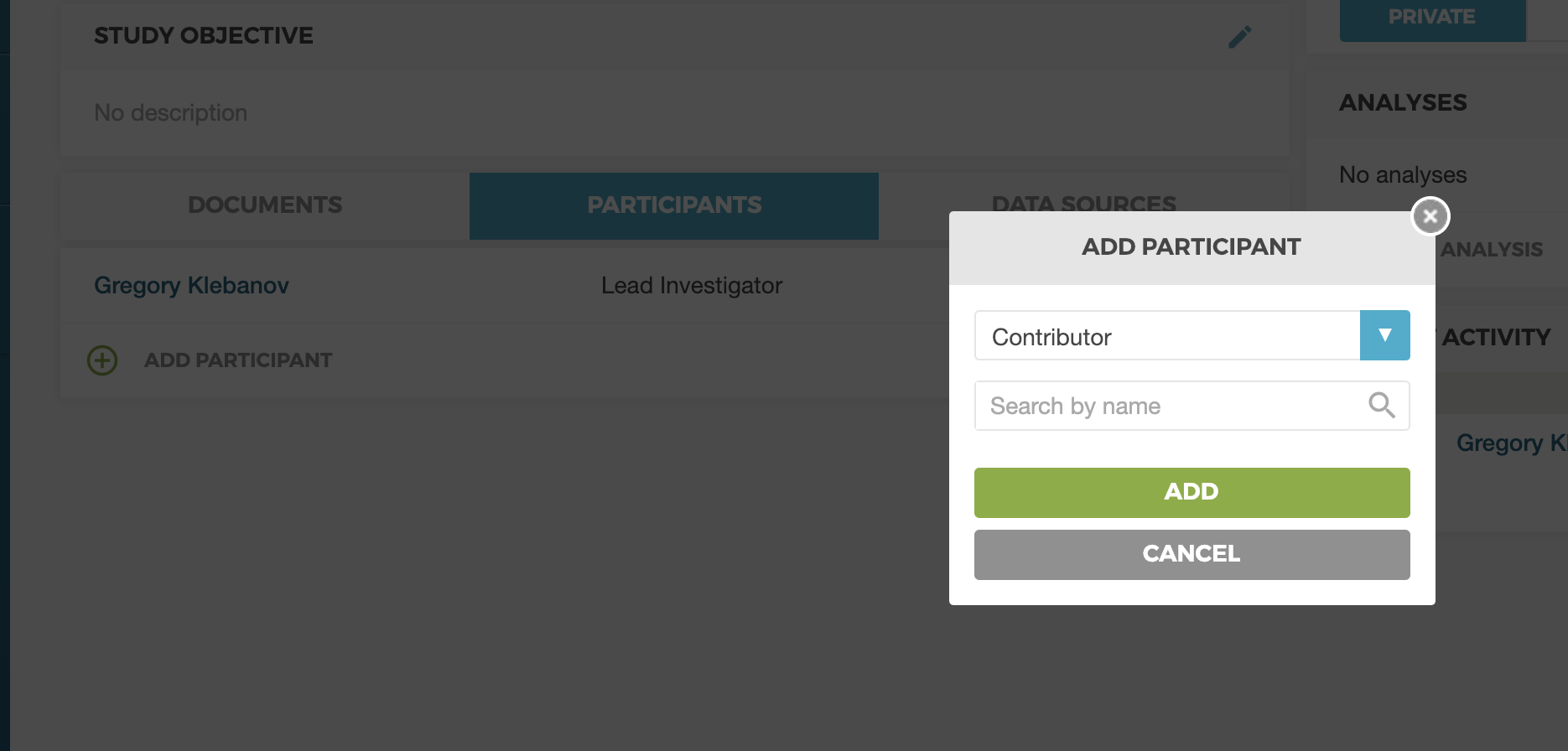
If you would like a certain group of people to not only see but participate in your study - please invite them into the study
and you are all set to execute it against data sets you added (assuming your code does not hard code connection or path info and was built with sharing in mind - see templated files fas an example of how connection should be coded)
After adding my repo to the OhdsiStudies as a submodule, I can manage the analytic code and the protocols by using issue and tagging. I can track each change in the codes and the reason in my repo.
Still, we need a web-based platform such as ARACHNE for better accessibility and convenience for most researchers. It seems that ARACHNE can execute the code uploaded to the ARACHNE by using dbConnector.R and main.R. Currently we do have sort of standardized population-level estimation and patient-level prediction package format generated by ATLAS.
It would be the best if the web-based platform for network study supports this standardized package format and can support this through the git repo link, not only through the uploaded code files. Then we can take advantages from both web-based platform and git for managing the network study.
It’s me again, and you will probably not like what I am about to say. Well, some of you.
After the Oxford study-a-thon, Henry and Patrick came to me and said that we have to allow the big R server touching the data install packages with the studies. Well, that is not going to happen. The security folks will not allow some code (read: virus) to be downloaded at run-time. Code has to be installed and checked. The fact that some dude downloads it does not help. What is Henry supposed to do? Reverse engineer the code to make sure it is kosher? And when we deploy it through ATLAS - where is the dude? And this is true for a US company. In Germany, France, China - don’t even think about it.
We need to have packages that can be preinstalled, and studies have to be configurations (through JSON or some other mechanism) of these preinstalled packages.
@Christian_Reich - Christian - thanks for bringing up this very hot and important topic.
In our little OHDSI ATLAS/ARACHNE WG, we have discussed this topic at great length, a lot of good ideas were exchanged. Good news - we seems to be on the same page on a need to have a standardized JSON definition for all key study elements, as well as studies themselves:
Concept Set
Cohort Design
Analysis Design (e.g. Cohort Characterization, IR, PLP, PLE)
Study (collection of the above)
That would allow us to do multiple things, including:
Share designs artifacts in a global shared repo
Exchange those between nodes in the network for the purpose of execution (as opposed to sending code like we do today)
Then, we have two schools of thoughts on what to do with JSON designs when it comes down to code:
have a number of pre-built components that can just use these JSON files as a set of input arguments
use JSON to generate code, including arguments that go into that
There are pros and cons for each. Would be wonderful to hear your thoughts on these, since you - and a number of other Healthcare and Payer organizations - probably have some pretty strict rules in terms of validation of components that are allowed to be brought into your environment from the outside. And I think you could actually achieve it with both ways - but let’s hear your opinion on this before we dive into this further
Greg, I like this approach but it’s missing a bit of an appreciation for reconciling the minutia of the current paradigm to run a study versus the newer OHDSI paradigm. We’re assuming that all end users are capable of mapping a question to our preferred input. I would argue that we may get there but that’s not where we are today.
To be honest, we have no real way, at the moment, to adjudicate a study question in a communal fashion without an extensive amount of hot potato JSON sharing. For instance, as we’ve been updating Ts and Os from the Live PLP exercise we ran at the US Symposium, there’s been no clean way to share definitions – we all use different instances of ATLAS and importing JSON definitions can be a real pain for the novice user. (Yes, I concede it’s trainable… but let’s admit, there’s a learning curve here even for the savvy.) We’ve had to set-up calls to align verbally and then someone takes the mission to update the T or O depending on what’s agreed.
I get that ARACHNE is intended as a communal workspace but in the absence of this being available across sites (which I’m hopeful will be a future state), we need to think broadly about a more sustainable – non-technology way, to make it easier to share the human piece of research, namely a priori assumptions. We lose new investigators when we complicate it with needing to know every detail of how a concept set works to build a cohort. I’d challenge we need to be able to help an investigator translate their ideal cohort with a few guided workflows.
Study questions die when we make it too hard. I’ve lived through two network studies this year and I still feel there’s a huge gap in how we get out of the gate. Even with the best preparation, we still have logistical constraints. I also believe a study question cannot be robust enough for a network analysis without the ability to characterize the question in multiple databases and making sure you understand what (if any) differences exist.
And sadly, there’s no R package if we can’t agree on who belongs in the T, C, and O.
So, perhaps I am a Grinch but I’d love to come back to Christian’s astute commentary on focusing on a technical specific solution:
Technology is important… but we also need a social change on how we think about iterating and how we adjudicate our inputs in a way we feel comfortable. Today, we are spending far too much time iterating in our respective silos and sharing JSONs isn’t expediting this.
In a technical perspective, I believe that standardized-JSON approach would be good and most feasible option for now, as @gregk said. None the less, my personal position is one of slight ambivalence. Because it would be hard to modify the analytic code generated by standardized-JSON approach. For example, I often add some custom features for PLP or PLE. And I found that it becomes hard to add this kind of modification to the package generated by JSON-based approach.
Again, this is a very personal view. For most other people, who don’t want to modify their analysis additionally, or who have better programming skill than me, it doesn’t matter.
As I tried to explain before, I agree with @SCYou: I don’t think passing JSON files around will allow the flexibility we’ll need. I predict that if we go this route, with every study we’ll have not only a JSON to pass around but also a new version of the software that implements the unique features required in the study, which defeats the purpose of having the JSON. Of course, I’m happy to be proven wrong.
I also agree with @krfeeney: Network studies require many iterations and shared interpretation across the network. In LEGEND we had a ‘feasability phase’ of the study where we just ran all cohorts and the propensity models, and discussed the results to see how things would play out in the various databases. This was very helpful and led to the modification of many of the cohort definitions.
One final thought: I keep hearing people say that git and R are too hard, and is only for the hardcore tech geeks. But we’re a community of Data Scientists. If git and R aren’t part of the shared skillset, what is?
Thank you for the support, @schuemie. I prefer more flexible way for further development of OHDSI ecosystem.
I love git and R, too. Still, we don’t need to limit our environment only to R and git. I don’t know it’s technically possible , but there might be a way to allow us to use both web-based platform and git/R together.
Interesting and important discussion. I agree with @SCYou and @schuemie that the ideal world of only specifying some parameters using JSON as engine will only work for very standard studies. My experience in running many federated studies is that there is always the need for some specific tuning and this would require changes in the underlying R Package.
With respect to “security”, I do not see the difference in a JSON specification that runs to a released R package which could also change over time, e.g. PLP, and the hydra approach which starts from an identical specification and builds a simple shell around the package with some for loops. The “internal guy installing the study problem” i think is a bit over the top in my view @Christian_Reich, are you suggesting he is also checking all the standard R Packages from CRAN? I do not think so.
I must also add that running federated network studies is something that is not new at all and has been done for a decade with many databases for example in Europe. In these studies we even have been sending around Java code that they ran locally and shared the results with us. This has been possible with all (>10) European databases I have worked with and are still working with. I agree with @Christian_Reich that direct access to the database without the “man in the middle” will not be possible for most data sources (including our own at EMC) because of governance and security reasons (this could change over time). However, I am also not too worried about this because we have proven already that you can get results back from databases in a very short timeframe. I do see possibilities for simple feasibility questions like how many people with T2DM do you have in near real time (by exposing aggregated data tables). This is being done already with hospital data but this is another level compared with what we are talking about here.
The key to all of this is building a trust relationship with the data custodians. The challenges we have are not technical but socio-technical. Building trust can be done by being transparent, invest in relationships, etc etc. If we build the tools and processes in such a way that we have open source code (for those that really want to dive in the details), study protocols (incl statistical analyses plan), contracts in place?, and have mechanisms for the data custodian to check what they are sharing in the end (so no locked down encrypted zipfiles), i think we are in a good position.
I fully agree with @krfeeney, this is completely inline with remarks I have been making for a long time. Standardisation of structure and vocabulary is the not completely solving the iteration problem of phenotype definitions across a data network. The feasibility step is needed and we need a phenotype definition library to avoid unnecessary iterations. For example, the lessons learned from these iteration steps in the LEGEND exercise are lost in my view (or I am missing this) and we only have the final results. We need to store the thinking process as well (versioning, annotation?).
“Git and R are hard”: we need to think about who we are serving here. I agree that a data custodian should have a data annalist that should have basic expertise. However, we can help the less experienced persons to execute a study by integrating more with our tools. For example, running a PLP from ATLAS or ARACHNE and pushing back the results to a viewer i think is feasible and would help a group of users we aim for. This does not (and should not) solve all the fancy research implementations but some basic functionality would be nice. Moreover, I think it would be very good if epidemiologists and statisticians learn the basics of git for version control. This should be in their curriculum. I know it is not at the moment but we also have role to make this happen (i am pushing this internally for example).
What? What happened to transparent and reproducible Open Science? I understand this is not mature and fully stable yet. But tweaking each time the code?
Huge difference: One is downloading code dynamically at run time. The other one is sending out a configuration file for an installed procedure, local (!) Hydra or not. The first: Practically no security, anything can come in and run on the data. Second: Trusted packages we can declare and stamp as “kosher”.
Exactly. The internal guy cannot do anything at run time. Has to trust. Many organizations will not allow that.
I am not saying don’t allow to share code. I am not. I am saying the standard way should be pre-agreed and pre-installed packages, with config files moving around. That can be done in a trusted fashion, no middle man and no complex IRB approvals necessary once established. But there should also be a “live code” JSON package. And then you can run hot code. But the governance will be very different. Those packages will not fly right through.
100% agree. But many custodians will not have the power to overwrite IT Security. For example @Christian_Reich won’t. It’s been made very clear: We will not have an R box available to an outside resource to run random code on the data in the DMZ.
And, even if we leave these folks behind: we will never be able to automate this unless we create the right trusted framework.
I actually think that both @Christian_Reich and @schuemie and @Rijnbeek have valid requirements that platform needs to support and they should not be mutually exclusive. This is the 80/20 type of the conversation
Yes, I also believe that we need to have pre-validated, tested and trusted packages where JSON will feed design as arguments. These packages will have known, agreed interfaces - in and out - so that we can enable not only automation of executing those but also receiving and processing results. I know a few organizations with strict IT Security and Compliance rules that would be very hesitant to
allow to execute non-validated, untrusted code that is coming from the outside. Not only that, but there are other factors such as a dependency on external libraries to be accessible and in many cases or libraries of the right version to be present - this can only be solved with trusted, pre-installed components. This is the 80 part
And yes, we should also support more complicated cases where code needs be tweaked. Or even custom code. Yes, there is an increased risk this case but security and compliance is always about risk management - we can think of a validation process that would be associated with cases like that. This is the 20 part
I see the ideal world scenario and we can get to this for standard studies, but the world is not always standard . Of course I agree to push for this as much as possible. However, the fact that you make a change to code does not necessarily mean you are not transparent or reproducible, you have to make sure you are.
Your argument holds if the R package needs no update.
My experience is different as mentioned in my post.
Not needing IRB approvals because you are using ‘approved’ tools, whatever that means, is in my view an illusion. If you mean you can establish standardized “simple” governance procedures for example because you do the same thing for another drug I agree based on previous experience and this is the way forward in my view.
I think we agree, this is also true for our data and most data sources I worked with. However, the semi-automated approach facilitated by a powerful tool like Arachne to support this process could work.
I think we agree there are different scenarios we have to support and this is not black and white.
@gregk can you explain how the organizations you talk about implement the process of “validating and trusting code”? Do these organizations use R and then “validate” all dependent packages? How?
Kristin - good point, you are absolutely right on a need of having a central place with shared designs!
Actually, that was one of the key discussions on why we need to adopt standardized JSON-based definitions for various design artifacts. We can imagine a central shared repository where OHDSI can start sharing a standardized definition of things e.g. phenotype/cohort, analysis design etc… with versions, annotations, links to where it was/is used, quality of outcome
Again, having standardized definitions will allow community to exchange designs and start creating a “meaning of things” - whether for the purpose of re-use (shared repo) or execution across the network (ARACHNE). Also, that could enable a number of other external cohort designer tools (hint-hint) to fall in line with OHDSI and start exchanging their proprietary designs with OHDSI community and vice versa
Two comments… in reverse order because this chain is moving faster than I can reply.
I 100% agree. We need to be more transparent about these underlying dependencies. I think @JamesSWiggins’s poster did a really nice job of showcasing the hodgepodge of versions that contributed to his own reference architecture.
It’s not just IT groups being strict. We have a bit of a messy approach in how we publish and maintain packages for analysis and for analytical tools. It’s not always “R and Git are hard”… it’s not always easy to retrace each other’s steps to install all these external dependencies. IT groups like to document these for SDLC but we also need to document better for overall reproducibility of results. I think our desire to put wrappers over certain things can make it difficult to recreate and validate a code.
JSON based sharing is OK for a technology approach but may leave something desired on the social approach. It’s not just about interoperability. It’s if we actually understand how to interpret the information once it’s shared. It’s a little like assuming one-to-many SNOMEDs are intuitive to someone who only speaks ICD-9/ICD-10… yes but… we all know how this story goes.
dear all,
This is an interesting discussion and I fully support what @Rijnbeek stated. Our experience across a multitude of multi database studies is that:
Tools can be re-used, but will need to be adapted for specific studies, so the code is often tailored to the study question
In my experience data access providers in EU (and also in other countries) always want and should be able to check the code. I understand this since they are responsible for privacy and quality that the evidence provided is compliant. They cannot hand this over fully
Transparency & readability is improved with a detailed study specific statistical analysis plan which should be part of each protocol based study and allow for easier checking of the code.
Data access providers should be involved to leverage local expertise, you can not assume that the same concepts actually means the same everywhere, that would be a critical mistake.
What would be perfect is a tool that supports the steps in the workflow
In each mature organization, there IT security and compliance processes exist, including:
IT Security teams work with software vendor to determine what packages are being installed and whether they post any risk from security and compliance perspective. Personally, I had to fill out very extensive and deep surveys and go through intense review meetings.
IT Security teams deploy automated tools that scan installed components for various things e.g. what is being perceived as malicious code, virus, license information
Infrastructure configuration is tightly controlled, including opening only allowed ports and allowing traffic only to approved IPs. Firewall is frequently blocking external traffic or allows it to very specific approved in advance DNS names.
Of course there is only so much that validation can do and this is where liability comes into play. We definitely do not want to be in a situation where someone would really try to run a malicious code on PII data or even a broader set of systems and see the headlines like this https://www.telegraph.co.uk/news/2017/03/17/security-breach-fears-26-million-nhs-patients/
and would want to prevent these cases by putting required controls in place right from the start.
Another thing we all need to consider. Today, OHDSI community is relatively small and everyone knows all active participants (aka usual suspects). As community is growing - and this is not the the case anymore - and we need to think about scalability which current process would not support.
This conversation touches on the foundations of our collective work to such an extent that I think it should lead to an external document that lives beyond this thread (chap in Book of OHDSI?). The point of being more formal would be to explicitly define design goals that have largely been implicit so far - or at least ones that I am not aware of having been formally codified or explicitly endorsed outside of some outstanding presentations.
The point of being explicit is to be as clear as possible about the relationship between strategies and agreed upon design objectives for supporting and conducting network studies.
That document could explicitly define OHDSI’s socio-technical system-level design points for conducting multi-site research.
E.g. OHDSI methods and practices seek to support the conduct of multi-site studies in ways that maximize efficiency by minimizing the effort and resources required for important research activities such as:
data wrangling
data development
study design parameters
human oversight
…
and maximize reproducibility by
public prespecification of hypothesis
transparency of code for source to CDM data mapping
transparency of code for study execution
…
It could then describe the choices about personnel, practices, IT, and tools, justifying standard strategies in terms of those design points. In particular, the justifications could explicitly address trade-offs between efficiency, reproducibility and other key design points. When there is a claim that a tool or practice increases efficiency without sacrificing reproducibility or vice versa, this document could clarify the justification for this claim.
OHDSI makes an unusual combination of claims about efficiency and scale vs methodological rigor. It (all you smart people) says “we’ve solved many of the most important bottlenecks that used to force you to be either efficient or careful but never both”.
Making the impact of strategies on efficiency and reproducibility more explicit will open up our assumptions about the personnel, IT, and institutional structures and activities to useful public scrutiny and improvement. It will also help define training needs and estimate budgets associated with study participation, etc. for sites that want to participate in ways that meet community expectations. And finally, it will help those outside the community understand the basis of OHDSI’s bold claims.
If this were to happen, my guess is that different sets of standards will evolve for different types of research and different types of community members.
 )
)

 . Of course I agree to push for this as much as possible. However, the fact that you make a change to code does not necessarily mean you are not transparent or reproducible, you have to make sure you are.
. Of course I agree to push for this as much as possible. However, the fact that you make a change to code does not necessarily mean you are not transparent or reproducible, you have to make sure you are.