
In the UK Biobank WG we discussed the problem of how to deal with Survey vocabularies. Here, we want to summarize the issues and discuss the possible solutions.
Looking at the initial proposal - while we definitely moving in the right direction, we recognize that there are still more questions that need to be addressed in the long term.
In short, the plan was:
-
Among the different vocabularies de-standardize and remap the question to identical questions (to avoid duplication).
-
Among the different vocabularies de-standardize and remap the answers to identical answers (to avoid duplication).
-
Among a variety of others, leave one distinct question as a Standard concept to be used for constructing survey-like detailed cohorts for users that need to research with all the granularity of survey source data.
-
Using the synthetic concatenated concepts or new MAPPING table to deliver the mappings to the Standard entities, recognized as useful in OMOP. So that, classic OMOP cohorts will provide the value they’re designed for.
-
Introduce new relationship_id ‘Has Standard answer’ to represent the list of the Standard answers for the entire Question.
The issues we found:
-
The questions from the various vocabularies provide very different context/peculiarities, so the mapping rate (questions to questions) is really low. Most of them are gonna be unique Standard concepts that will eventually overload the Standard survey vocabulary.
-
Every specific answer list shades the meaning of the question concept, so the borderlines to be defined in every single concept.
-
Proposed modeling doesn’t address the problem that survey-like cohorts still requires referring to the source survey concepts.
Here is an example (all the concepts below never existed in the mentioned vocabularies, they are synthetic and only created to reproduce the problem):
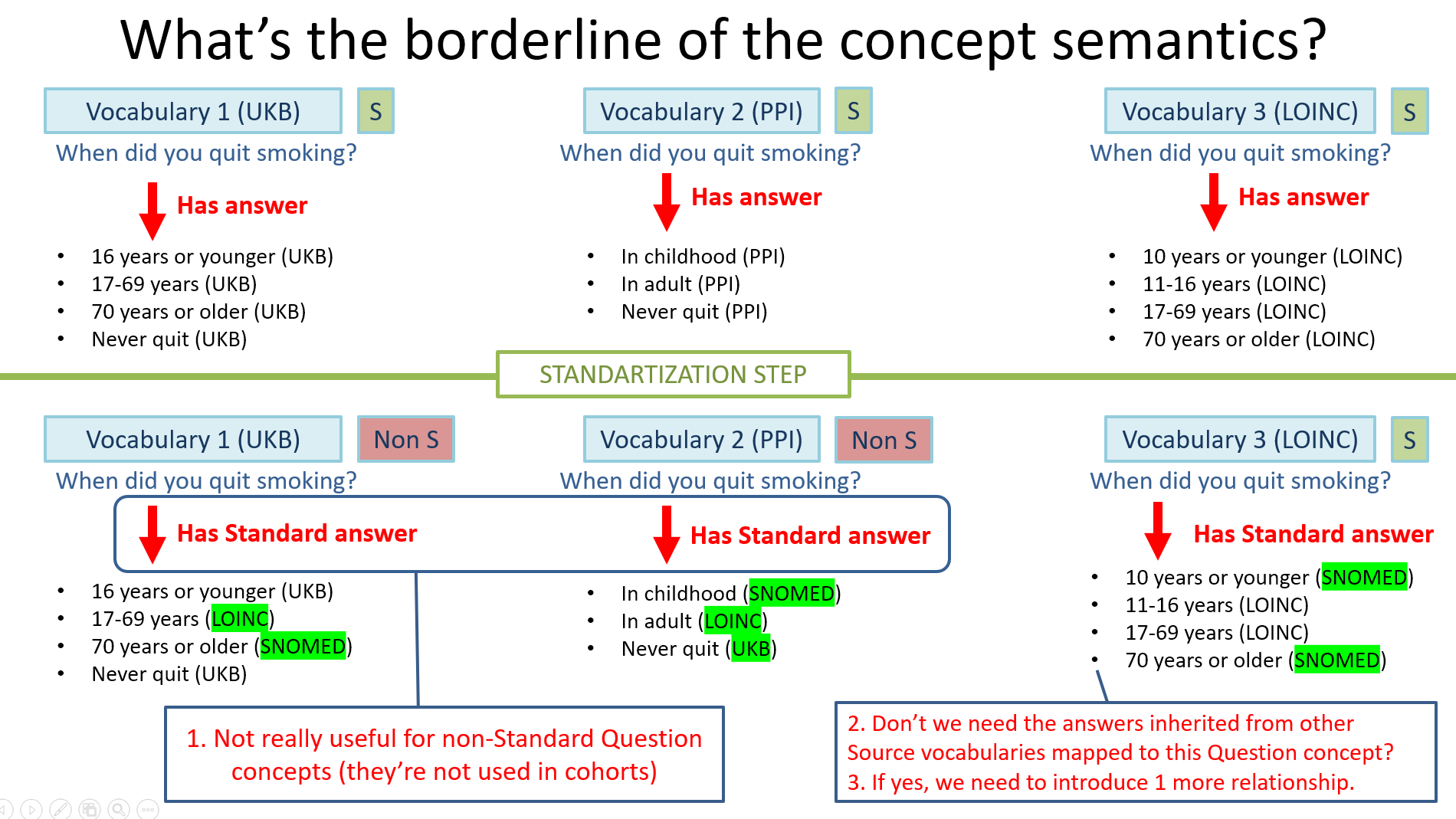
The concerns on the slide are:
- ‘Has standard answer’ link is not really useful for non-Standard Question concepts since they’re not supposed to used in cohorts. For Standard ones, it may be found useful, but only in the Measurement Domain.
- If you don’t know the whole list of the possible answers used with a particular question concept, you can’t build universal survey-like cohorts anyway. Every time you still need to jump back to the source vocabulary to check the answer list used (and the mappings of the non-standard answers).
- If we put the whole list of the answers derived from many source vocabularies mapped to this particular Question concepts, we’re gonna deal with the ugly mixtures: year ranges (including the conflicting ones) together with categories of different sorts/axes. Technically it may work on the vocabulary side (even though requires a substantial effort to maintain), but not supposed to be user-friendly. Moreover, for many of the Questions you can get the full semantics of the concept only once looked into the list of its answers. Do we want to mix such sort of things?
From here the vocabulary team has started thinking about alternative solution:
The proposal we come up with is turning all the Survey Question/Answer concepts into non-standard. Meaning that we’re still able to build the survey-like detailed cohorts, but using the source_concept_id only. Mapping to the Standard valuable facts will be provided as described above.
And here we come to the CDM limitations:
-
To build the question/answer pair-like cohorts in the _source_concept_id area, we would need to have the _value_source_concept_id field as well as value_source_value field. The former one doesn’t exist in OMOP, the latter one introduced to the Measurement table only.
The addition of these fields will resolve the problem. Otherwise, we would need to create these ugly pre-coordinated question-answer pairs forever. From my point of view, the pre-coordination in the survey data is even worse (doesn’t represent the survey source structure, difficult to understand and maintain). -
When v6.0 was released (I checked this pdf), the survey_conduct convention described how the survey data should be stored. Now I can’t find anything out of it on cdm60.utf8
Is it outdated, placed somewhere else or just lost?
It said the following:
Patient responses to survey questions are stored in the OBSERVATION table. Each record in the OBSERVATION table represents a single question/response pair and is linked to a specific SURVEY/questionnaire using OBSERVATION.DOMAIN_OCCURRENCE_ID and SURVEY.SURVEY_OCCURRENCE_ID.
Each response record is the response to a specific question identified by the OBSERVATION_CONCEPT_ID. This concept ID is a unique question contained in the CONCEPT table.
An individual survey question can have multiple responses to a question (e.g. which of these items relate to you, a, b, c). Each response is stored as a separate record in the OBSERVATION table. The name (question) is stored as OBSERVATION_CONCEPT_ID and the value (answer) is stored as OBSERVATION_AS_CONCEPT_ID where the answer is categorical and is defined as a concept in the concept table, OBSERVATION_AS_NUMBER where the answer is numeric, OBSERVATION_AS_STRING where the answer is a free text string or OBSERVATION_AS_DATETIME.
The question / answer observation record is linked to the patient questionnaire used for collecting the data using two new fields in the OBSERVATION table; DOMAIN_ID and DOMAIN_OCCURRENCE_ID.
DOMAIN_ID for any survey related observations contains the text Survey and DOMAIN_OCCURRENCE_ID contains the SURVEY_OCCURRENCE_ID of the specific survey. This domain construct can be used for other observation groupings.The OBSERVATION table can also store survey scoring results. Many validated PRO questionnaires have scoring algorithms (many of which proprietary) that return an overall patient score based on the answers provided.
Survey scores are identified by their OBSERVATION_CONCEPT_ID and are linked back to the scored survey using the same DOMAIN construct described.
If we move the survey vocabularies into the non-Standard area, it requires an updated convention:
-
Question-answer pairs (being non_Standard concepts) will be presented in the source_concept_id and source_value_concept_id fields only. Observation_concept_id and value_as_concept_id fields will be used for Standard target concepts only.
-
The specs says that besides others the possible answers in Survey data are numeric, free text or dates. So the observation_as_number, observation_as_string and observation_as_datetime fields are still “occupied” by the “source” Survey data and we can’t use them in the context of the entire observation_concept_id.
We drafted a couple of examples to better understand two options:
(a): store all the types of the survey answers in the value_source_value field only (concept_code, numeric value, datetime or string). Populate the source_value_concept_id field when the answer is a concept. The survey ansers will not be sorted out into the observation_as_number, observation_as_string and observation_as_datetime fields. These field will be used in context of the onservation_concept_id only.
(b): always intentionally create a separate CDM record for the target standard Observation concept. So that the Survey “source” data is always captured as a separate CDM Observation record, and answers can be sorted out into the observation_as_number, observation_as_string and observation_as_datetime fields. It’s a little bit against the basic principle of data transformation in OMOP. Would it be easy to implement on the ETL side? What would be an indicator of applying such transformation or sorting between Survey source and Standard records? New ‘Survey’ Domain, being not a new table, but a characterictic of the concept, may be a choice in the long-term run.
We would like to hear other ideas and get feedback from the community.
Tagging the working group and people involved in the survey data discussions before:
@Alexandra_Orlova @Andrew @anna_corning @aostropolets @Chris_Knoll @Christian_Reich @clairblacketer @cmkerr @ColinOrr @Daniel_Prieto @Dave.Barman @Dymshyts @ellayoung @ericaVoss @gregk @Josh_R @kyriakosschwarz @lee_evans @linikujp @MaximMoinat @mcantor2 @mik @mmandal @MPhilofsky @mvanzandt