I agree with your approach of starting simple and scale up if driven by use cases. The first use case of having the frequently used SQL queries in an App is a good start. I suggest we lay down the functionality for that using the markdown approach and extend from there.
Execution against your database is a nice to have thing I agree and we can make that an option in the App so you can deploy it with (locally) and without (centrally).
I would personally not link up the central one with a database.
I had a discussion about DSL earlier with some people. Personally, I think the best way to train people on how to use the CDM and the Vocabularies is to use SQL as this is the most expressive way. The SQL library will make the queries accessible for more people (you can replace the drug of interest etc) and moreover we have tools like Atlas that produces general results for users without SQL knowledge.
However, I am not a DSL expert nor user, so it may be valuable for others. I do think for the tool we are talking about now it is bit off an overkill indeed.
To test, clone the ‘shinyApp’ branch and open an R console in the main folder. Then execute:
library(shiny)
runApp('omopQueryApp')
It should open a Shiny window with the G01 OMOP Query pre-selected. If shiny is not installed yet on your system, execute install.packages('shiny') and install.packages('shinydashboard') first.
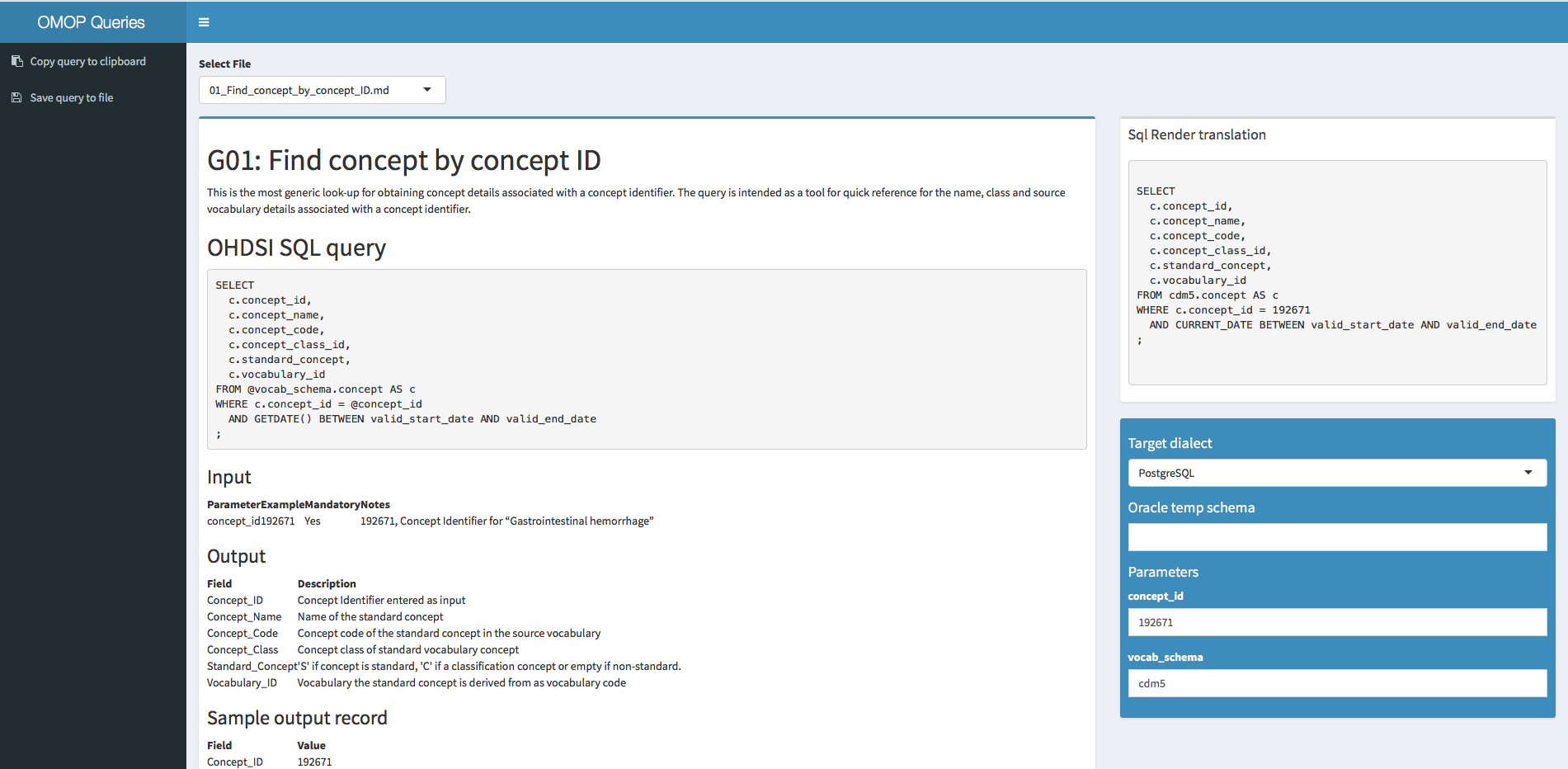
All that the app now does, is rendering the markdowns in the OMOP-Query repo and extracting the sql part for translation. For that, I have blatantly copied the SqlDeveloper shiny app by Martijn.
Any feedback is welcome! Please do note that this is a first version. Especially the file selection box has to be replaced with a filterable table, with metadata from the markdown files (like domain and table target).
This is a nice introductory to the community! Am joining now and I can feel the energy…and that the community is also vibrant with shinyApps too. I would love to contribute on this. Just let me know where things stand and what needs to be done:-)
Thanks for moving this forward. Just returned from US, I will have a look at this on Monday and will give my feedback. Would be great to get the input from the others as well.
Welcome to the community. Can you send me a private message to explain a bit what your expertise is etc and why/how you like to contribute to this specific topic.
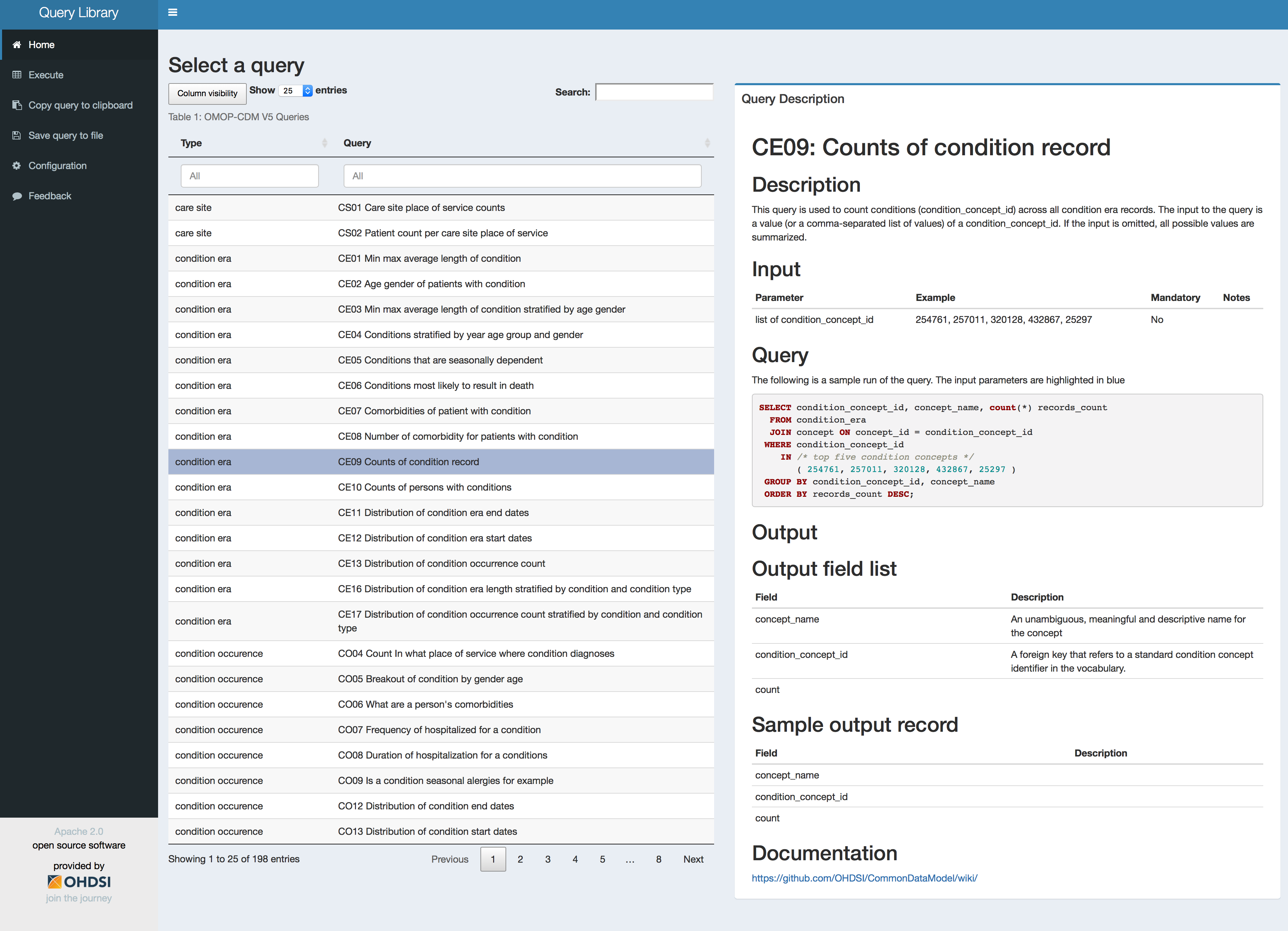
Added a table that is automatically filled by all the markdown query files. Type = subfolder name. It allows for filtering and search. The description is taken from the markdown filename (replace _ by space, and remove extension).
Automatically render a HTML version of the query you select in the table using the SqlRender that translates the sql in the markdown to the selected dialect in the configuration tab (pretty cool). This is displayed on the right. This allows for auto colors in the sql.
Added a configuration tab with schemas, server details etc. if @cdm or @vocab is in the markdown sql this is replaced on the fly. I do not think we need more parameters in the sql (like done automatically in SqlDeveloper App).
Execute tab added, but functionality still needs to be added. Ideally i like the query to be editable so you can change the input parameters before your run. The table below will show the results of the query.
To be discussed:
We need to standardize the markdown files better, some have missing content, different order of elements etc.
It may be nice to allow for a userfolder that you can specify in the configuration. All files in this folder will then also be automatically added in the table, i.e. you can add to the standard library content if you want on top of the validated once.
Would it be possible create new queries, modify existing ones?
Add parameterized queries - that can be rendered in sql-render
Would be nice to have a API like functionality - that gives fully rendered sql back to another app. e.g. another app may want to report the number of people by gender in a cohort, and age distribution of the cohort.
This looks great! (although for some reason I get a lot of ‘disconnected from server’. May need to debug some more on Chrome).
For me and others like me that need to do things that are not supported by existing tools I think this is just right: I can quickly find queries for everyday tasks, and perhaps modify them as needed. My end goal would be to create some custom SQL based these example that may end up in one of my own study packages.
I think others like @Gowtham_Rao have very different use cases that I’m still struggling to understand. Here are my 2 cents:
Query sharing: If you have queries that are generic (like the ones already in this library) that you think are useful for a wide audience in a wide variety of settings, then I would say these should be added to this library. However, if the queries are specific to one study, they should just be in their own study package.
API and parameterized versions of the queries: I’m not sure I understand the use case here. To my point above: if you’re actually looking for an easy way to implement studies that you can distribute to data partners, I suggest creating a study package.
I will have a look at the Chrome issue, not sure why that happens.
Yes, I agree. The purpose of the library is to have access to often used queries for re-use and also for training purposes, e.g. in a training we can refer to query G04. If there are often encountered questions on how to perform a certain query on the CDM we can add these to the library through Github issue/pull request. We can add a validation procedure by the package maintainer.
Parameterized SQL is already supported in this version but I have limited this to @cdm and @vocab in the queries that are rendered on the fly using the settings in de configuration tab (see for an example the visit query). It can be made flexible to add a query dependent parameter box but for now I think this is a bit of an overkill.
If you run it locally we could add the option to define a user folder that adds your own queries on top of the once provided by OHDSI potentially, but not first priority now.
I am not so sure about making add/edit query options in the APP itself available (definitely not on the community version that would mean we need to add user accounts etc which is a bridge to far i think).
In general, this is already a useful resource as is. More functionality is not strictly necessary. Two small things we can improve: 1) add more metadata to the queries, so they can be found more easily. For example the tables being queried. 2) An additional cleanup of the sql files. For instance ‘sysdate’ is not translated properly (in OMOP SQL it is GETDATE()).
This is great @Rijnbeek.
I wish this existed (or i knew about it) when i first started learning SQL and writing queries for the CDM.
One addition that would be useful would be a filter to select queries for a specific type (e.g., to see all the queries for drug exposures) without having to scroll through the whole list. Especially if this list begins to expand or the types become more granular.
A quick update. I have created a new Github repo https://github.com/OHDSI/QueryLibrary
that contains an R package you can install and then you can run a shinyApp. I had to move this to a new repo because the OMOP-Queries name is not following the best practices (no dash in the package name) and I think QueryLibrary is a better name.
I have recorded a short video that demonstrates the app following @anthonysena good example when we were working on other stuff (sorry for the somewhat low resolution but you get the idea)
Hi Peter, how far is your team with adding the other sql scripts? In other words, for which queries do you still need help?
Last week when we spoke in Brussels, you mentioned a tool to check the rendered queries against multiple databases (also used for SqlRender). It would be nice to build an automated query validator. Where can we find this tool?
Hi @MaximMoinat we have added other queries as well and are testing these.
Indeed it would be nice to have this option in the query library for testing purposes. @schuemie shared information about this and we are implementing code for this. Maybe we can meet at Erasmus and work on this together next week and brainstorm a bit on the use of the query library for the EHDEN training etc.? I will send you an email.