The requirements can possibly talk more about how good is a given computable phenotype.
Scenario: Accessing Phenotypes with Known Performance for Predictive Modeling can be a bit improved.
E.g., the concept of sensitivity of a given computable definition. (all other related terms).
The document may try to define those better. If my IsSmoker phenotype is declared to be Gold Standard Phenotype Algorithm but has sensitivity of only x%. I may still not use it since I require at least y% sensitivity.
@SCYou, you’re right. For a time, we were using * to denote required fields, but it looks like those didn’t make it in this draft. I’ll be sure to add that back in on the next one.
For validation, the idea is that you would only enter the four true/false positive/negative values because these are the fundamental building blocks for all other metrics. From these, we can derive everything else like the total number of cases, sensitivity, specificity, PPV, F1 score, accuracy, etc. In the case of a chart review, you might not always have values for the true/false negative cells (i.e. looking at charts for those whom the algorithm did not choose). That’s ok. The values for those cells would just be 0 for that particular validation set.
We’ve proposed having a form where you’d have cells or boxes to put those values in prior to submitting the form.
@Vojtech_Huser, I’m not sure I understand this point here. Sensitivity is a measure of how well any classification algorithm performs, regardless of whether it is a computable or rule-based phenotype, or even another algorithm entirely.
If you’re referring to how the sensitivity for a computable phenotype is obtained, I’ll defer to @Juan_Banda regarding APHRODITE’s internal validation procedures and @jswerdel for his work on PheValuator to get at sensitivity for any phenotype algorithm.
Indeed! For exactly that reason, the “Gold Standard” portion of the library doesn’t prevent cohort definitions from entering due to their metric values. A sensitivity of x% may be good enough for Person A but not for Person B, and there will never be a “one size fits all” solution for every phenotype. That’s why one of the principles of the library is to make searchability a priority; once you choose a Book (phenotype), you can see all of the Chapters (cohort definitions) that are available to you. A user can sort them by any metric, filter them, and otherwise organize them to find what works best for his/her particular use case.
Thank you for your questions @SCYou & @Vojtech_Huser, and I hope that helps to clarify some things. To you and every else, feel free to reach out with any other questions you may have!
Great work in writing this up! I like the detail in the document, and in particular appreciate the explicit evaluation of risk. This may have been discussed earlier regarding citation tracking, but would we want to consider additional identifiers for publications (e.g., DOI, PubMed ID, etc.). To keep with the requirement of making citation submission easy, these could be optional and possibly something we ask a librarian to curate?
@lrasmussen, thank you. Yes, I think that makes sense and is a good idea. For the citation entry form, we could toggle between DOI, PubMed ID, and something more manually entered like a BibTeX entry. If you or others can think of other relevant IDs used for citations like DOI or PubMed, please let me know.
All, I won’t be able to meet at 10am today, but I am looking forward to discussing the library at noon on the community call!
@apotvien Shouldn’t we submit the information about the number of ‘how many records cannot be classified into positive or negative?’ in addition to true/false positive and negatives?
When I did manual chart review, I couldn’t classify more than a half records into either ‘true’ or ‘false’ in case of GI bleeding.
@SCYou, that’s interesting. Nothing stops us from adding an “Inconclusive” category to the mix to represent records that were inspected but indeterminate. Out of curiosity, what were some of the aspects that made classifying the records impossible? I’m curious if this was a feature of the data, the cohort definition, neither, or both and if it’s something that we can possibly get at with the right question(s).
Usually it happens because of missing data (non-informative texts only in the discharge note).
But specifically in case of GI bleeding, we cannot often find definite evidence of the bleeding even though GI bleeding is highly suspicious and we performed endoscopy. So, even though the patient said that he/she had hematochezia or hematemesis, we don’t know what exactly happened whe he/she arrive at the hospital. If there are many inconclusive cases, then overall accuracy of the cohort can be suspicious…
Thank you kindly for the opportunity to present at the community call this past Tuesday. I’ll be re-reviewing your questions, concerns, and suggestions from the recording.
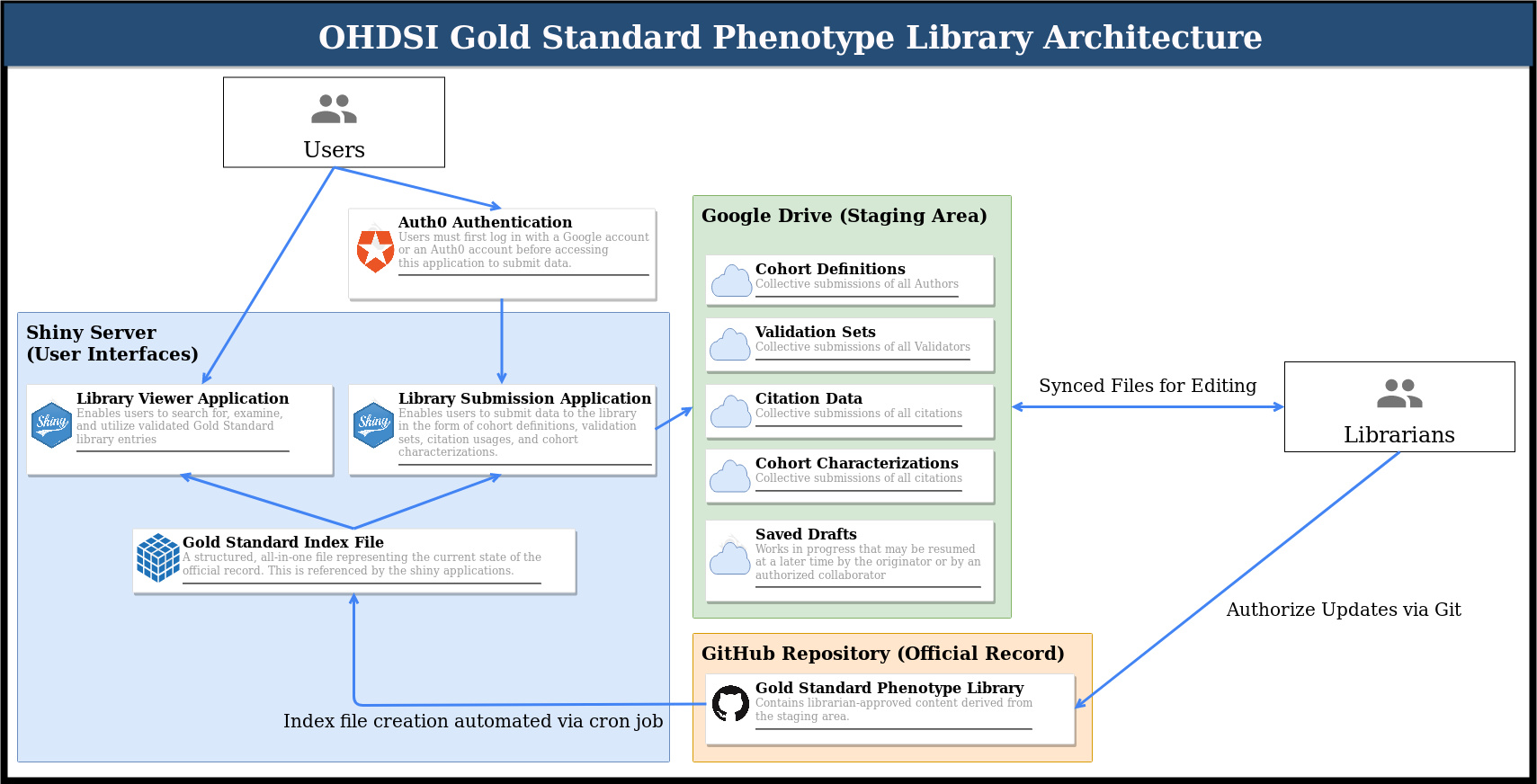
In advance of the software demonstration at the symposium, I wanted to release this updated architecture diagram, which I believe more clearly articulates the cycle being proposed. After the symposium, I’ll be writing up the technical specifications in more detail, but the diagram below outlines the process. I expect to have a working proof of concept for this particular configuration at the demo.
Users have two Shiny applications which they can use to interface with the library in different ways:
The viewer application for read-only activities (i.e. examining, searching/filtering, and/or downloading cohort definitions). This is a space where we can display whatever kinds of charts, diagrams, tables, etc. people find useful when they are trying to locate a cohort definition.
The submission application to propose adding new data to the library, which requires authentication with a Google account. Currently, this is being carried out with Auth0 using the auth0 R package. The idea here is that the librarians would have access to the full Auth0 dashboard, which has a lot options that comes with it (details left to future tech specs document).
The types of data being submitted I’ve been calling “modes of submission”. You might want to submit a cohort definition of your own, or submit validation data for someone else’s definition. You might want to submit a citation for a library definition that’s been used in a publication, or you might want to submit a cohort charaterization so others can anticipate what their cohorts may look like when they execute the cohort definition at their site.
Whatever the case, when data are submitted using the corresponding form within the Library Submission Appplication, the data are processed and then uploaded to a Google Drive service account dedicated to the library.
Librarians can then clone the gold standard phenotype library repository and sync to the Drive folder. Every librarian who does this becomes one with the staging area, so to speak. Any changes made online on Drive or locally on the librarian’s computer will show up for all other librarians as the changes sync. This is also true as the Shiny application uploads its submission data to Drive; the newly uploaded data will sync for all librarians.
The staging area is not the official record though, as proposed submissions may take varying degrees of consideration (peer review) before they are ready to be elevated to OHDSI’s official library. When a staged change is ready to become official, the librarians can add it to the repository via standard git commands, thereby taking ownership of that particular update.
Before the content can reach back to the viewer/submission applications, an index file is necessary to compile the data into a single object. This essentially allows the applications to run and load far faster than they would if they had to query the repository and perform all of the calculations at runtime. A simple example of this is with metrics. Recall that we ask for raw true/false positive/negative values; we therefore calculate the sensitivity, specificity, PPV, NPV, F1 score, and accuracy “behind the scenes” so that the applications can display the numbers without first having to calculate them. Another example is provenance, where we calculate connected components so that we can display a network graph for a given cohort definition to show all of its relationships to other definitions. The index file is also an opportunity to insert other advanced calculations and pre-loading mechanisms that have not yet been foreseen.
Finally, a cron job can automatically rebuild the index file on the server by periodically checking the index file timestamp against the timestamp of the latest commit to the official record. If something has been pushed to the official record after the index file was last made, then the index is due for an update and will be rebuilt with the updated data from the official record. This advantages the librarians, because once they have pushed an update to the official record, they don’t need to worry about anything else, as the index will automatically update on its own. We could also consider a git hook to tie the automation more precisely to a commit event, but that would place more burden on the librarians to ensure the hook is configured and executing properly.
This completes the cycle! When a user checks back into the library applications, the updates that the librarians have brought to the official record will appear.
As a mentioned in the call, the requirements of the library are conceptually separate from the technical specifications, but I think both can advance simultaneously to some extent. A good example of this was when @Patrick_Ryan raised the idea that having cohort characterizations would be a good mode of submission. From a requirements perspective, this currently needs its own set of data elements to be specified; precisely, what do we expect users to submit when they add their own cohort characterization? However, from a technical perspective, it’s relatively easy to extend the Library Submission Application to incorporate one more type of submission.
I’ll be on the line during our regularly scheduled WG meeting (Tuesdays @ 10am ET) for those who wish to discuss this further. The week after, we’ll cancel the meeting since most of us will be at the symposium, which I’m very much looking forward to!
This is a follow-up to the Requirements Document. This time, I have gone into much more detail about the rationale and capabilities of the services being proposed to facilitate each step in the architecture diagram in the post above. The document covers information about Shiny, Auth0, Google Drive, and GitHub. As with the Requirements Document, feedback from the community is welcomed.
I appreciated the enthusiasm for the library at the software demonstration last month!
P.S. As of today, we have decided to modify our WG meeting schedule in time and frequency. We will now meet monthly the first Tuesday of each month from 11-12 EST; our next meeting will be on November 5th.
Hey Aaron - See below for comments and questions that arose while I was reviewing the technical specifications. Many of these are things are related to conversations we’ve had on prior calls but I noted them here. We can discuss these on our next call or I am happy to provide additional clarification where necessary. Feel free to call or email me. - Mitch Conover
On page 3, (below Figure 2), you first raise the book-chapters metaphor. I think that it would help to enter an earlier paragraph that introduces the concept of a book/chapters before you get into the details about how to use it. Without some introductory context, it seems abrupt.
Regarding the description of the submission application form (p4), I’m wondering if it is a likely use case that a user would be uploading a citation for a phenotype they didn’t add? If so, does such a user need access to the whole submission application menu if they are just going to add some information about citation usage? Is there a way to append just the citation?
I realize you plan to clarify this in future iterations of this document, but do you have an idea for the format (e.g. free-text) for uploading the citation usage and cohort characterization portions of the submission application? E.g. citation usage could draw from a standard reference file generated by the National Library of Medicine (PubMed) or from Google Scholar (EndNote). Will the cohort characterization be the corresponding JSON file?
What if a user identifies a problem or error with a given phenotype that they don’t own? Who do they contact about revising it? The original creator of the phenotype? The librarian? How can the user info for these people be accessed?
Is there any security that prevents a user from directly revising someone else’s phenotype? What about creating a duplicate copy and tweaking someone else’s phenotype? Would the path of original ownership be discernible after multiple users generate derived copies of a phenotype?
o Based on my read of p9, it sounds like the answer is yes it will. To be fair, I’m less familiar with Git than your average user but the process is not totally clear to me.
If I have a group who defines phenotypes I really like (e.g. psych-related phenotypes coming out of individual X, who is part of group Y at institution Z) can I search and upload other phenotypes that have been produced by that individual? By that group? By that institution?
Regarding the description of the cohort characterization portion of the submission application (p4) is there any regulation around ensuring compliant data reporting on the website? E.g. What if people post Medicare data with cells that have N<11? What if someone posts a characterization that’s clearly not useful (e.g. uses inpatient data only to report the proportion of patients who have diabetes). Is this a problem for OHDSI in terms of breach-of-data regulations or would it only be a problem for the person who posted it?
It sounds like some of the design requires that the OHDSI web team at some point transition the OHDSI Shiny Server from HTTP to HTTPS. As someone who is totally ignorant here, how hard is this? Should we begin reaching out to the web team to explore the feasibility?
“Content from the Staging Area gets promoted by the librarians to become part of the Official Record” (p8). What is the promotion process? Who serves as a librarian? What sort of expertise do they need with respect to: 1) content / therapeutic area, 2) study design / methods, 3) databases under study?
Does the current description of the system assume that each index file corresponds to a single phenotype applied within an individual database? Some phenotypes may perform differently depending on the database (e.g. an EMR-based vs. a claims-based dataset). Also, the ability of PheValuator (or a given xSens or xSpec dataset) to assess performance might differ depending on the database (by data type, health system etc…). How would the system link together the same definition which has been run / evaluated in multiple data sets? Are those each chapters within a single book? Do we want to encourage users to think about outcome evaluation on a database-by-database basis or across databases?
Hi @conovermitch, thanks for the feedback here! Let me address these questions one by one, and feel free to reach out to me as well if you have any follow-up questions/comments.
For this technical specifications document, I was intentionally trying to not go too deep into book/chapter details like we did in the requirements document. That being said, I agree that an introductory paragraph can be added.
For those who are still wondering about the books and chapters, @jweave17 had a great poster at the last symposium (here) that nicely summarizes the book/chapter layout and associated metadata.
Yes, submitting a cohort definition and submitting a citation are completely separate forms. This means that it is possible (and likely) that you could upload citation information for someone else’s cohort definition. The citation form will be very small; essentially, you’d select the cohort definition you’d like to reference and then add in the reference material.
It’s true that the details of this have yet to be worked out in terms of what is exactly being submitted here. From an abstract point of view, we know we want to be able to reference real-world applications of gold standard phenotypes. We also know we want to have details about what types of cohorts are likely to result after application of a given gold standard cohort definition.
Allowing for dropping in a PubMed or EndNote citation file is a good idea. It will expedite the process and prevent errors that are associated with manual data entry. We might also allows a generic BibTex entry (this can be considered free text I suppose, but more structured). Suggestions for other modes of citation are welcome, but I think this is a good starting point.
Regarding cohort characterization data format, I don’t know whether a JSON file here would be ideal or not. I’m going to ping @jweave17 (again) because I believe he is working on a cohort characterization tool and therefore might be able to help out here as to what a good output format of a “Table 1” would be.
In this situation, either option is possible and probably depends on the nature of the problem/error. For contacting librarians, we’ve considered having a librarian mailing list that individuals can use. Contacting authors directly is also possible because the author e-mail addresses are a required data element at the time of submission.
Since you need to log into the submission application before submitting any data, we are able to associate users with the phenotypes that they own. Hence, they cannot directly revise someone else’s phenotype unless they have been granted access (via a shareable key) from the originating author. As with plagarism in general, one cannot categorically prevent someone from wrongly copy/pasting content and claiming it as their own. In the library, we have two mechanisms to mitigate this:
The first is provenance, where at the time of submission, we allow cohort definitions to cite other ones in the library. This can be done for a variety of reasons but its intention is to track phenotype evolution and to give credit where it is due. A chain of provenance would reveal the path of ownership all the way back to the root node, in traditional graph fashion.
The second is the librarian team to mitigate any conflicts not resolved by the provenance mechanism.
Do you mean search and download instead of search and upload? In general, you can sort, filter, and/or search on any of the required data elements as you see fit. This includes authors and institutions.
@jweave17 can you comment on this? Do you have any provisions in your cohort characterization tool to check this sort of thing?
I’ve reached out to @lee_evans about this, and I was pleased to learn that this is something that was already in the works and will happen completely independently of the library. Therefore, we should no longer be concerned about the necessity of the HTTP-to-HTTPS transition.
The promotion process simply means that content has been pushed to GitHub by a librarian. When it lives in the staging area, it is a temporary place hidden from public view where the content can be worked on. When it is released to GitHub, it becomes “sanctioned” as the public record. The process would probably involve librarians meeting up at a regularly scheduled meeting to review the content and agree to push all or some of it to GitHub.
The questions you ask about the librarian qualifications are good ones, and we should discuss this at the next WG meeting.
I’m not sure I understand what you mean when you say “each index file”. If this is regarding the Index File section on page 5, there is only a single index file (an RData file residing on the server) at any time. It holds all of the pre-processed data for the library, and its only purpose is to allow the applications to perform better. It’s faster for the applications to reference pre-computed values to display than it is to force each application instance to perform the same computations individually. It is derived from the Official Record via an automated R script.
The database issue is an important one, and I think it comes down to clarifying intended use. I view this kind of like a contract. If I submit a cohort definition, I should have the option of specifying whether its intended use is for EMR or claims-based datasets. Then, subsequent validations would only be legitimate if run on a dataset meeting the authors’ specifications. For example, it would be unfair to declare a cohort definition to be poor performing if the authors specified that it is to be run on EMR-based data, but it was actually validated on claims-based data.
The chapter is linked 1-to-1 to the algorithm, so if the underlying instruction set changes based on the database specification, then those would become separate chapters.