We decided to cancel the Western Hemisphere plp meeting tomorrow.
On Thursday we will have an initial discussion on how to incorporate the PLP pipeline in the webtools and how to visualise the results. We will prepare a presentation on this topic for our next plp meeting in two weeks to get your input.
if time permits, or perhaps to put as a placeholder for the next call, id
like to hear the group’s thought on the following question: ‘what is a
risk factor?’ we keep learning models and evaluating performance, but the
consumers of results keep coming back to this question. but is a ‘risk
factor’ just the variables selected by the model? is it any covariate with
a univariate association with the outcome? or does finding a risk factor
require population level estimation to observe a causal effect,
conditioning on all other factors? how does the definition of ‘risk
factor’ play out in a world of many highly colinear covariates, where many
alternative models may yield equivalent performance?
Hi, @Patrick_Ryan
It is not easy to understand your question for me…
I think the purpose of risk estimation by machine learning is not identification of risk factors. But I want to find risk factors, too.
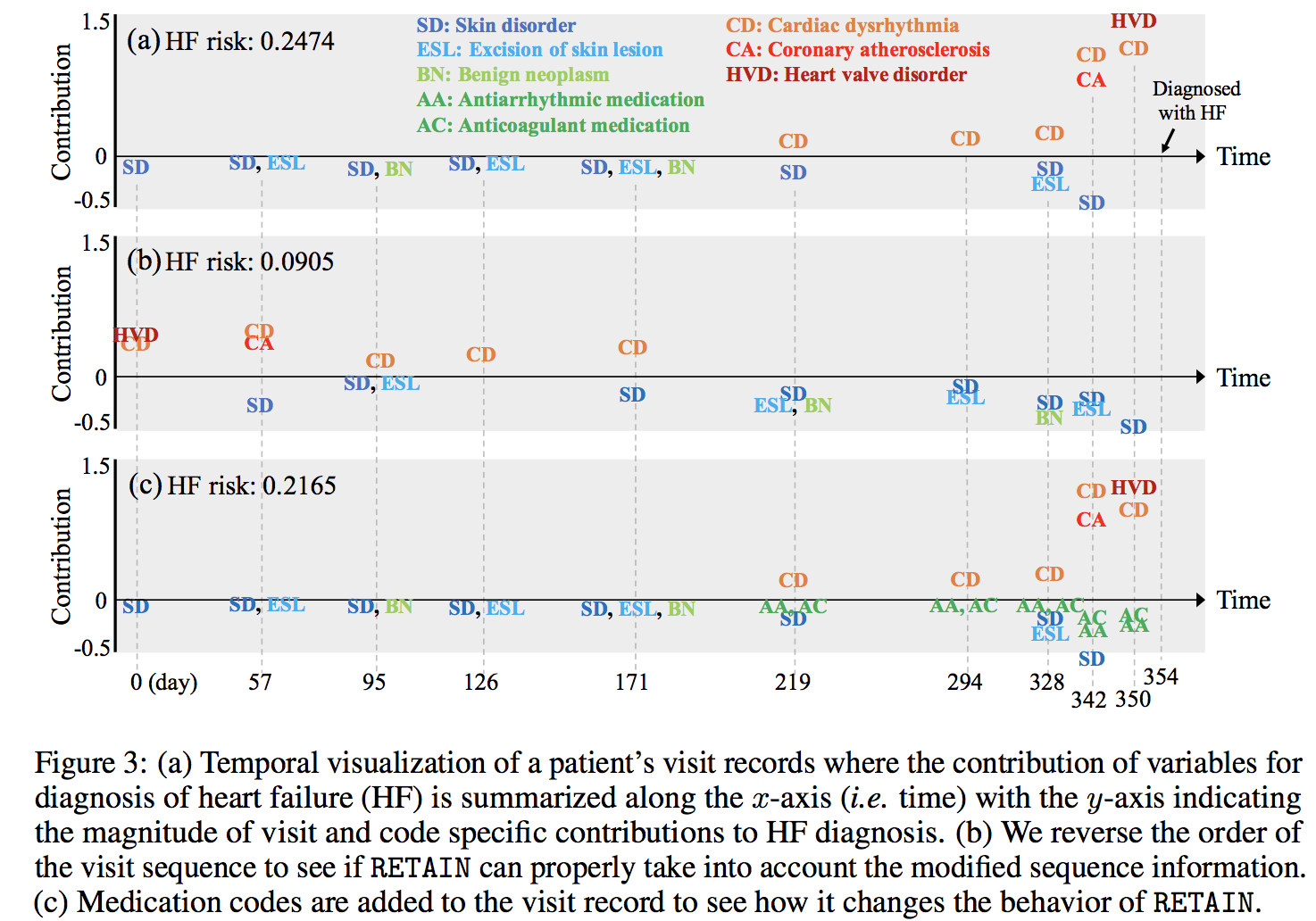
The picture I attached is from articles of RETAIN (arXiv:1608.05745 [cs]), which used deep learning (RNN) with attention model. They tried to predict heart failure. In this picture, you can see that arrhythmia, athersclerosis and heart valve disorder is strong risk factors for HF. What is interesting is that anticoagulant medication and antiarrhythmic medication seems to have negative association with development of HF in the same patient (maybe preventing progression of coronary atherosclerosis).
Like this, I believe we can show that which factors confers benefit and risk for the patient by using machine learning. Moreover, I want to show the association between progression of underlying risk factors and the disease (such as relationship between progression of DM and the development of myocardial infarction). This is one of what I want to develop.
As I said, I didn’t fully understand your question… So I’m not sure this is the answer you want.
Tomorrow Chan will update us on the progress on implementing the doctor AI algorithm, plan for a paper, and some ideas to develop the deep learning track.
Tomorrow we will have a look at the results of the Proof-of-concept study in Depression patients from the databases we received so far and like to discuss next steps.
In the Eastern Hemisphere meeting tomorrow Sungjae will present on distributed logistic regression and I will give an update on the large-scale prediction study.
Sorry for hijacking this thread, but just wanted to share this whitepaper I stumbled on. It’s on a piece of software called Hunchlab that is used by the US police to predict crime and plan deployment.
Some technical details are noteworthy, like their use of time-related features that also make sense for us given the observed temporal dynamics in our data, or the use of a Poisson model to calibrate the predictions. I also like how they offer to measure the performance of the software on the data of a particular police department (‘more [data] is better’, ‘cleaner [data] is better’).
But what I really like about this document is how they present prediction to (power) users: the name Hunchlab to me is a stroke of genius, being quite modest (e.g. in constrast to Precrime) and so not too threatening, but also how they relate the workings of the algorithm to how a police officer would go about trying to predict where crime is most likely to occur next.I think we can learn something here on how we communicate prediction to doctors.
I guess they have the advantage of being able to boost their predictive power by adding true positives to the data after predicting them, if necessary.
On Wednesday in the Eastern Hemisphere meeting Seng Chan You will present results from a study of predicting 5-years risk of cardiovascular disease using a 3-layer GRU model.
The goal of today’s Western Hemisphere meeting was to brainstorm about the Prediction Tutorial we will prepare for the OHDSI Symposium. Unfortunately, multiple key team members cannot join so we decided to cancel today’s meeting.