Friends: This is funny. How about we collapse all votes with first names that are also a main character in Tolstoy’s Anna Karenina into a single Yes vote and restart counting.

| OHDSI Home | Forums | Wiki | Github |

Friends: This is funny. How about we collapse all votes with first names that are also a main character in Tolstoy’s Anna Karenina into a single Yes vote and restart counting.
How about we collapse all votes with first names that are also a main character in Tolstoy’s Anna Karenina into a single Yes vote and restart counting.
The voting rules haven’t stated that only a single person from an organization could vote. What is more, I don’t think that any of the voted people have contributed to OHDSI less than any other average OHDSI member from a different organization. And, overall canceling or influencing legitimate voting smells too Russian
I am not saying only a single person from an organization could vote. But when all of a sudden all these Elenas, Natalias, Igors and Konstantins without participating in any of the previous conversations discover their love for the LOCATION_DISTANCE table then I think it makes sense to combine them all under the user “Anna Karenina”.
Look: This is a community effort. Adding tables has a cost, particularly if it is a convenience table only very indirectly related to patient data. The cost has to be offset by use cases people actually need. So, rigging the vote is not useful, in particular since we have no denominator (some kind of electorate). We have to treat each other with that kind of understanding.
So, how about this: We have the votes “Anna K” and “Andrew and Robert” really in favor. We have a couple votes being cautious about adding a table like this. Let’s figure out if there is a compromise. If not, we add the table.
We needed @Christian_Reich and @gregk on the CDM WG call when this was discussed. 
The valid issues that @Christian_Reich raise were discussed then. @clairblacketer and others should correct me if they disagree, but I think gist of the conversation headed toward a consensus that we give the table a provisional status in a development branch to reflect our uncertainty about whether this strikes the right balance between cost and functional requirements (not convenience).
We, @rtmill and I, don’t plan to use this as the solution in the GIS WG. But we clearly recognize and appreciate the hard and thoughtful work that @pavgra did in getting something to work. This tentative solution is one way to get around the difficult requirement of being agnostic for all OHDSI-supported databases - rather than requiring a separate PostGIS instance with lots of helpful GIS functions for example. And it does that in a way that supports several, if not all, important real use cases.
Getting GIS data to relate to other data in the CDM and supporting GIS-specific functions is complex in many ways. This table might not end up being the best approach. But it is a potentially valuable step forward. The development branch status clearly marks it’s level of maturity.
As our fierce leader @Christian_Reich often admonishes, we shouldn’t let the perfect be the enemy of the good.
@pavgra here are the results of the vote:
It seems like there are differing opinions on whether this table should be accepted. Since it has such a slim margin I think we should continue the discussion before making a decision. Let’s do this - either I or you can start a new forum thread calling for participation and arguments both for and against this table. Once the arguments are made we will bring them to the next CDM workgroup call to hash them out. Hopefully we get more alignment this time around.
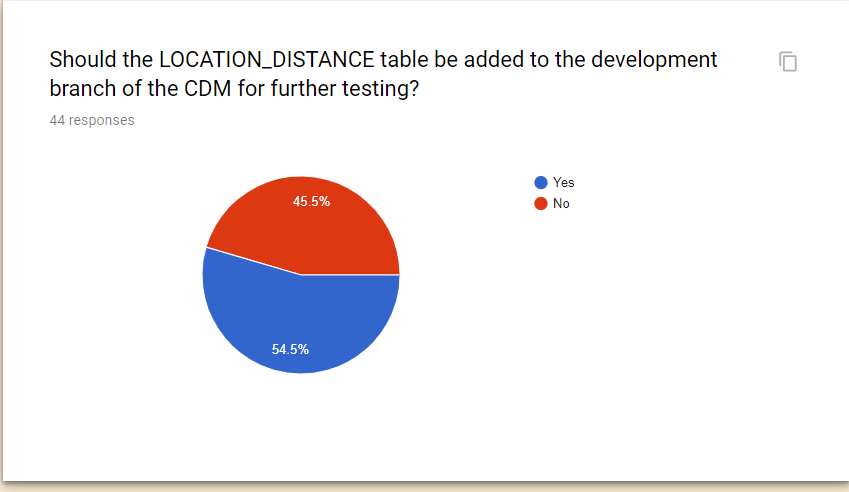
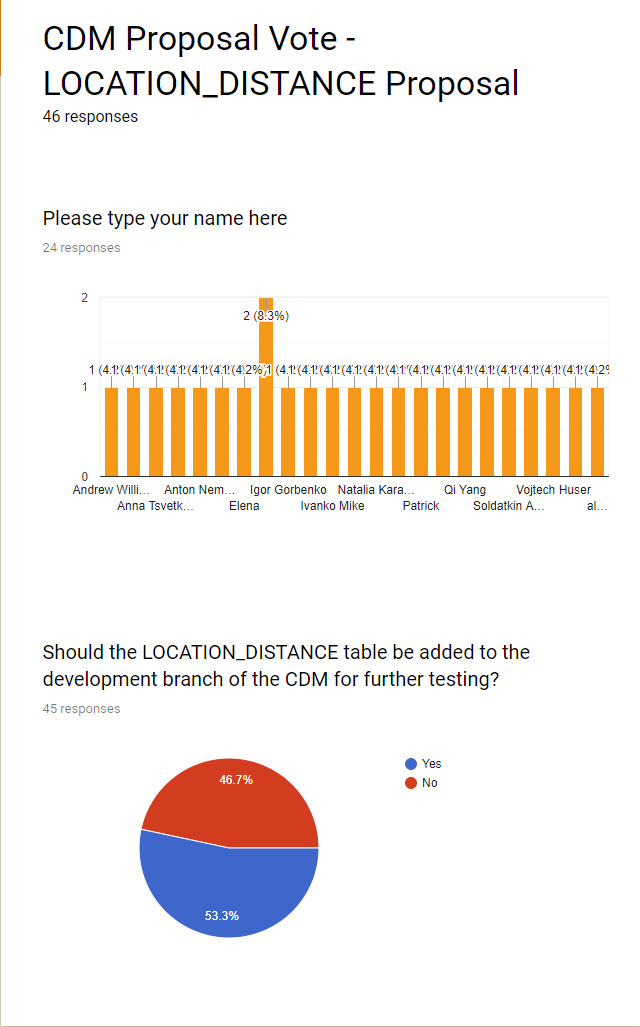
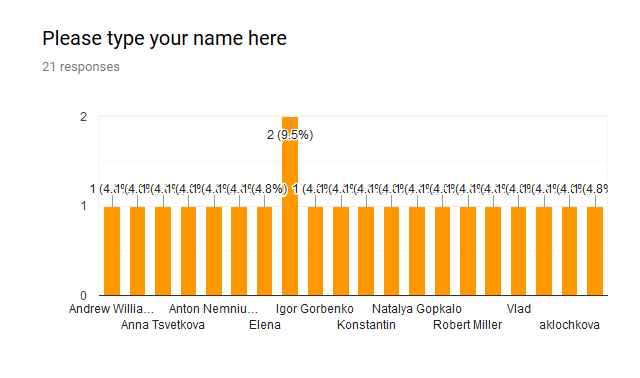
Wow, what a turn. So do we count these anonymous voters? Do you even know who are those 20 people clicked “No”? And whether those are not a single person?
And what about region_concept_id?
@pavgra just to be clear, the graphic that Christian showed is not the number of people that clicked ‘yes’ it just shows the number of people who voted. One person voted twice which is why you see that tall bar in the middle.
@clairblacketer, what I am talking about is:
Please type your name here
23 responses
Should the LOCATION_DISTANCE table be added to the development branch of the CDM for further testing?
44 responses
Is there a chance to see who are those 21 anonymous voters? If no, why do we count them?
I voted against this proposal and agree that I think it warrants further discussion before we recommend adoption by the entire community. Apologies that I could not make the last CDM WG call, so let me use this thread to express the reasons for my reservations:
I could imagine one use case, which I’ve seen from past work by other colleagues who aren’t currently part of the OHDSI community, where they want to study whether a patient’s ease of access to a hospital facility (as measured by the distance from their home to the nearest hospital) has an impact on their health outcomes. For the papers I’ve reviewed of this ilk, the general approach is to define a cohort as patients who have been admitted to a hospital for a specific reason, then classifying that cohort based on distance to that hospital, then comparing some post-admission outcome between those with close proximity to hospital vs. those with far proximity to hospital. In this case, i always assumed that this type of analysis was conducted by first creating a cohort, then computing the covariate of ‘location distance’ to the specific care site for the qualifying patients in the cohort, then creating some binary variable for ‘close/far proximity’, then executing their regression model to assess the impact of proximity, conditional on other patient characteristics. I would be quite interested to hear from our community if I’m off-base or if others have implemented similar studies in a different way.
The proposed solution seems to be suggesting that we need a data structure to store/cache derived information that can be computed from the core CDM patient-level data, with the justification that computing this information at analysis time is less efficient than pre-computing the information during ETL time and looking up the derived value at analysis time. We don’t have any precedent for expanding the CDM - a patient-centric data model to store longitudinal clinical observations - to store attributes which are neither verbatim source data elements nor patient-level nor time-varying attributes. Currently, the CDM has limited derived elements in the core schema: the notable example is the DRUG_ERA table, which is patient-level and serves as an expedient because it was recognized as a very common use case across the community that some may want to aggregate drug exposure records to the active ingredient level to represent spans of time of persistent use, which can be used to define cohort criteria or features used in characterization, estimation, and prediction. LOCATION_DISTANCE, as I understand it, is not person-level, not time-varying, and does not provide a directly actionable information (because you have to join to the source location and destination location to infer the context for the the calculated value).
It seems there could be other alternatives that can be considered before we resort to a computing a cartesian product of all location-location pairs. Per #1, I need to understand the motivating use case better, but I have a very hard time imagining that most location->location distances would ever have material value in any conceivable analysis (let alone being a commonly used element, which is what I would prefer to see before considering making a community-wide requirement for adoption). If the use case is anchored to a particular care site, then it seems we should be relegating this activity to analysis time, and then it can be the design decision within the analysis routine as to whether a cartesian product should be pre-computed and cached or if computing location distance for the specific subset of location-location pairs is good enough. In either case, this doesn’t feel to me to be a CDM conversation, but an analytics tool conversation.
It feels like we’ve now spent a disproportionate time talking about ‘location’-related data modeling activities in the CDM WG, but I still don’t see many community members coming to the table that actually have locations in their source data, nor do I see much location-dependent evidence being generated by our community. I am concerned if any location-related solution isn’t going to be used by the GIS WG that @Andrew and @rtmill are leading, nor is it being used by our colleagues at Ajou who have previously presented their AEGIS work. I know that I am not alone in being challenged by the fact that most of the source data I have access to do not provide granular location information (some have 3-digit zip, some have state, some of census region, some offer nothing), so most of these solutions seem completely non-applicable.
All that said, I don’t see why @pavgra or anyone else can’t try to build out a prototype solution to satisfy emerging analytics use cases based on whatever data structure they want. I just don’t think that this exploratory development has to be ratified by the entire OHDSI community as part of the OMOP CDM or OHDSI toolstack. If there’s real community-wide demand for the use case and solution, then it would be good to hear broader support from multiple stakeholders to ensure that the burden of changing the CDM for the entire community is offset by realized value of new evidence from a reasonable subset of the community.
My apologies for jumping into the discussion late. I am following the discussion without being an active part of it so far, but there are many good points being brought up. In my experience at a provider, we used location distance to analyze outcomes but also to operationally see where there could be deficiencies in service areas geographically. To me, location_distance has a strong EHR/provider bias use-case.
@Patrick_Ryan brings up a good point, if we we can model it as part of a prototype for a specific use-case, that would be a great next step to showing its usefulness to the community.
@clairblacketer - I know that person. He was up in the air at the altitude of 27,000 ft somewhere over the state of CO trying submit his vote over superb quality WIFI offered by AA. It made me think that not only latitude and longitude matter but the altitude as well, let’s add it to OMOP CDM 
@Patrick_Ryan - many good points you brought up here
@Patrick_Ryan - back in October @Gowtham_Rao posted a very good proposal on GS. Just wanted to make sure you didn’t miss it.
@Gowtham_Rao - where are you (a rhetorical question ), we need you here
The OMOP CDM is truly a great a model, no doubt. But with data keep growing exponentially, we really need to discuss how we model in a such way that it can continue to scale. Do not want to start a philosophical debate on modeling and DB designs here but are we designing a model for a large scale data warehouse or is CDM just a logical model? If just a logical model - then you are right, there is no need to express the derived concepts here. However, then we probably miss the point of properly designing of a derived physical model and implementation. The physical model is a representation of the logical model and is organized in a such way where a) it takes advantage of the database-specific implementation (we kind of do it) b) it is targeting the intended use and is built to for speed and scale. So, de-normalizing and pre-computing during ETL is quite a normal practice in the DW world. The model and even SQL that we use today already suffers from scaling on DW databases and we end up throwing more and more hardware into that. Not to continue in this thread, but I think this is a topic worth good discussion and review of our approach.
At the same time, the points in #3 are good.
@Patrick_Ryan, @clairblacketer, @Christian_Reich, keeping the location_distance topic aside I’m still trying to figure out what’s going on regarding the location’s region_concept_id which did seem to pass the voting. Could someone shed the light on it?
Friends:
How about this:
Makes sense?
I’ve been heavily lurking on this chain with great intrigue. I feel a bit like the Mueller report. No real conclusion and yet the dialogue is telling.
The idea of enabling location-based analysis has a lot of applicability into public health studies. Perhaps we need to engage some of our friends at the CDC (@rjking – maybe this is where you could help  ) and better understand the intent of how these fields would be used in analysis.
) and better understand the intent of how these fields would be used in analysis.
I voted “No” to the proposal and here is the reason. There are also many other location related attributes and other dimension related attributes out there. If we have to add them one by one as a new column into the current dimension tables (Location, Provider, and Care_Site), it will be hard to scale and not economical. So we need a more holistic approach to the issue which I have propose in this thread:
So if we can adopt this new approach, we can certainly add more attributes (including region_concept_id) without disrupting the existing dimension table structure. The future addition of any new attribute will become adding a new concept instead of adding a new column and that will be a lot easier. Sorry that I was not able to attend last CDM work group meeting. We typically have client demo on Tuesday 1 pm.
@pavgra this was added to development.
One note - the Sql Server, Postgres, and Oracle DDLs, constraints, and indices are fully supported and tested. The scripts for BigQuery, Netezza, Impala, Redshift, and Parallel Data Warehouse are available on the development branch but they are not tested. Instead, they were created by translating from the Sql Server version through SqlRender. This may or may not impact you but it is an important change to be aware of.