Thanks for that. I’ll give it a try.
Robert Clark
| OHDSI Home | Forums | Wiki | Github |

Thanks for that. I’ll give it a try.
Robert Clark
In reading over the report, “Safety of hydroxychloroquine, alone and in combination with azithromycin, in light of rapid widespread use for COVID-19”, it appears the patients whose data was collected weren’t tested for COVID-19 at the time. So it would take an additional expense to track these patients down and administer COVID-19 tests. In other words, it would not just be a matter of data collating. And even then you wouldn’t know when the patients contracted it.
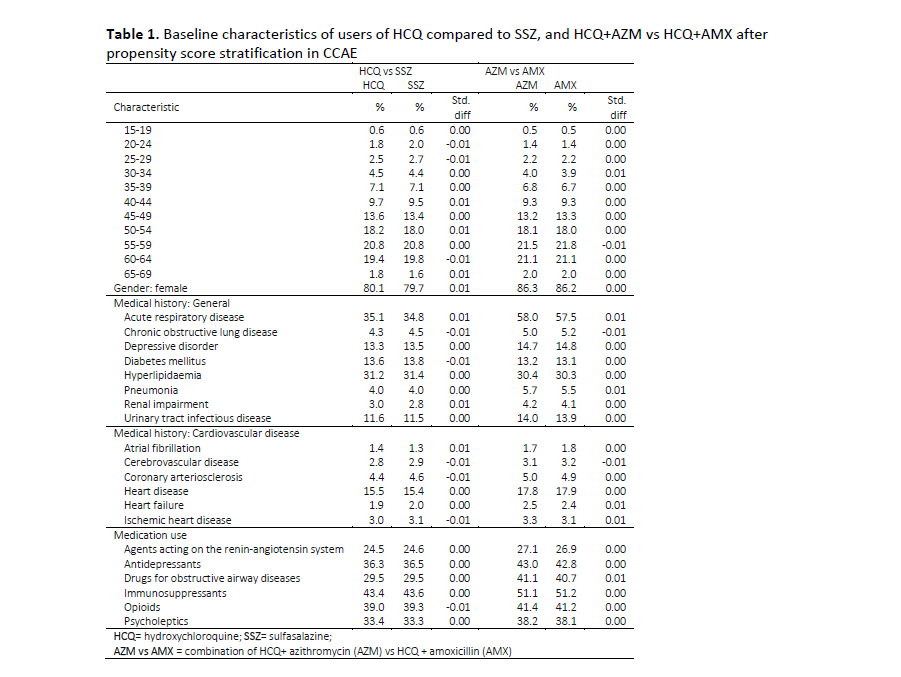
There is also a puzzling line in the report in Table 1, p. 16 in the list of patient health conditions:
It’s the line in the selection above showing the percentage of “Acute respiratory disease”. The numbers are quite high across the table. But HCQ is now given in the 6 industrialized nations that the cases were taken from for disorders like lupus and rheumatoid arthritis, not for things like malaria. I don’t believe ARDS has a high incidence in those illnesses. So was this high incidence of ARDS because a large number of these cases were taking HCQ as treatment for COVID-19?
That complicates matters if so. Because we’re trying to find cases that were already taking HCQ long term and then see if they contract COVID-19, not those who started taking HCQ because they had already contracted COVID-19.
We might still be able to use this fact however, if we do have access to these patients follow-up health histories. We could see how many recovered from the COVID-19 on HCQ and the various combinations with and without HCQ.
Because of these extra complications I still prefer the idea of the FDA putting out a request to all doctors treating COVID-19 patients to send in their health histories to see how many of them were on HCQ. This would be just a matter of data collating, so much cheaper to do.
Robert Clark
I believe all this data was from 2000 - ~2019 from existing datasets, so likely no one had COVID. It really was intended to explore the safety of the combination in light of the information that both have some small risk of QTc prolongation.
@Robert_Clark - the side effects of hydroxychloroquine are well known and documented on the drug label. The other problem with the drug is it has one of the longest serum half-lives of any drug I’m familiar with (24 days; almost all other drugs half-life is measured in hours). Certainly lupus and rheumatoid arthritis patients can be studied as part of an observational search as OHDSI is able to do. I’m don’t know what the total patient population of those on this therapy are. A lot of patients are being shifted over to newer medications including biologics.
FDA has limited authority to require the type of data you are seeking. They can require establishment of patient registries if there are potential issues that need post-market studies and these are largely for safety. In this case, the drug has been on the market for years and there are now a number of generic manufacturers. To solve the problem you pose, one needs to search across medical records and link those to Rx prescriptions. This is easy to do in large HMO databases such as Kaiser Permanente but more difficult in other community settings where small practices cannot be easily searched.
A potentially powerful use of the OHDSI network is to extract information on natural progression of Covid-19 to help design better Covid-19 drug trials. For example, test the influence of different inclusion/exclusion criteria that are being used in various clinical trials on outcome measures & possibly recommend different criteria to increase the power of different trials. Most of the trials I’m reading about enroll all adults >18 years old. But it might make more sense to do an enrichment design and enroll only older patients, e.g >40 years old or patients with certain risk factors for worse outcomes, especially since many trials are receiving funding for only a few hundred patients. We need those trials to be as informative as possible (not an inconclusive result that the trial was underpowered and therefore need more patients). As an example, test different I/E of Covid-19 positive patients & construct Kaplan-Meier curves for death+use of intensive services, which was already one of the outcomes that the community has a cohort definition for Some trials are using the WHO 7-point scale as the primary outcome measure. PEEP is used as an endpoint in NCT04312009, Time to CRP >3x ULN in NCT04326790, max level of troponin during hospitalization in NCT04355143. We could report mean values and standard deviation in current Covid-19 patients so that biostatisticians are able to do the power calculations. Information will definitely be helpful for trials currently being designed. And it might not be too late to get existing trials that are not too far into recruitment to do a protocol amendment for the I/E so that they are more powered for their endpoints.
The excellent presentation from @Tudor Oprea from IDG at the April 14th Community Call could be the starting point (though when I click on the Excel file link, I get a 404 Error @MauraBeaton is that something you can fix?) Does that file already include Trial No., Title, Number of Patients, Randomization Allocation, Age Criteria for inclusion, Other inclusion and exclusion criteria, and the Primary Outcome Measures, whatever else you think is important to capture for this exercise? If not, would it be difficult to do? Then we can identify common I/Es and Outcome Measures and construct K-M curves or other outcomes and make those results available to the Covid-19 trial community. Will need help from this community to figure out what endpoints to prioritize, biostatisticians, people who know how to construct study packages, and of course people who have the Covid-19 data. I’m happy to organize the group (could we get a channel in the Teams environment to collaborate on this?) Welcome feedback on this idea.
I also got the same error message when I tried to open the linked excel spreadsheet linked to the awesome presentation by Tudor Oprea.
Thanks for that, @Mark_Shapiro. The line for “Acute Respiratory Disease” (ARDS) also shows a high percentage for those on AZM. In this case though it makes sense since AZM is prescribed for pneumonia.
Through a google search I found references to pneumonia appearing in rheumatoid arthritis cases. Then patients taking HCQ for rheumatoid arthritis could also be diagnosed with ARDS. That line for ARDS for HCQ patients still seems high though.
By the way, this data set might actually be useful without the expense and extra time of testing every one in the data set for COVID-19. The reason is the number of cases of COVID-19 in a country is for those confirmed as by a COVID-19 test or clinically confirmed symptoms, or hospitalization. The actual number of those simply infected is an unknown number with varying estimates, since many are asymptomatic and wouldn’t take the time to be tested.
Then for this data set we would also be looking just at confirmed cases which should be available in their medical histories.
The percentage of confirmed COVID-19 cases worldwide is in the range of 1/3,000. Then the number of confirmed cases in this data set of 1,000,000 people would result in the range 300 cases if HCQ is not protective.
Better though would be to break down the numbers in the data set into the number of cases in each of the 6 countries. The reason is COVID-19 does not have the same prevalence in each country.
Anyone know what are the numbers of people in the data set for each country?
Robert Clark
Just saw this:
Robert Clark
This study reviewed a data set of over 4,000 confirmed COVID-19 cases in New York:
There were hospitalized and non-hospitalized cases. Certainly, for the hospitalized cases the doctors would have taken the prior health histories, so it could be determined if they were on HCQ. For the non-hospitalized cases they could do follow up to determine that.
The prevalence of lupus and rheumatoid arthritis in the U.S. is about 1/100, most of whom take hydroxychloroquine. If HCQ is not protective we would expect that same proportion in this group, so about 40 cases of those on HCQ appearing in this data set. Were there?
Edit:
Another study on confirmed cases of COVID-19, this time from China:
Clinical Characteristics of Coronavirus Disease 2019 in China.
The New England Journal of Medicine.
February 28, 2020
DOI: 10.1056/NEJMoa2002032
https://www.nejm.org/doi/full/10.1056/NEJMoa2002032
This one had over 1,000 cases and also collected health histories.
Robert Clark
A new proposed treatment uses Pepcid(famotidine):
In a review of 6,212 medical records, with many patients on ventilators, the doctors in China found that only 14 percent of the elderly people using famotidine died while 27 percent of elderly people on omeprazole passed away.
Scientists suspect that in COVID-19, famotidine binds to the papainlike protease, an enzyme which helps viruses replicate in the body and stops them replicating.
US scientists have used the 3D structures of 2003’s SARS coronavirus to predict the behavior of the new coronavirus, COVID-19.
Testing 2,600 compounds on the new protease, they found several dozen that proved promising in how they interacted with the protease but pharmacists have narrowed it down to three, one of which is famotidine.
After getting approval from the FDA, Northwell – which runs 13 hospitals in New York – used its own money to start a blind double trial.
On April 14, the US Biomedical Advanced Research and Development Authority (BARDA), which operates under Kadlec, gave Florida-based Alchem Laboratories, a $20.7 million contract for the trial. The money is reported to cover most of Northwell’s upfront cost.
Interesting doctors in China were able to make the association reviewing 6,000 patient medical records.
Imagine, the number of drug associations that could be made with nearly 1,000,000 COVID-19 medical histories to review.
Robert Clark
My proposal was to search for medications in the reverse sense, by looking for drugs missing from patients medical histories, suggesting the drug might be protective against the disease. But that article above shows big-data can find effective medications in the direct sense, by reviewing large data sets of patients medical histories looking for drugs that patients with positive outcomes had in common.
The article explains the doctors in China noticed rural patients with severe disease surviving better than city patients with severe disease. They hypothesized it was due to rural patients using the cheaper Pepcid to deal with heartburn.
The doctors then confirmed there was a statistical association between Pepcid and more positive survival rates. The point I’m making though is by reviewing such a large data set of 6,000 patient histories the computer could have identified that association even when the doctors had no inkling there was a link.
This method then can be used to find other medications that had a positive influence on patient outcomes, even when doctors are not aware of it.
That report I discussed earlier on New York COVID-19 cases had a data set of 4,000 cases, 2,000 hospitalized and 2,000 non-hospitalized, “Factors associated with hospitalization and critical illness among 4,103 patients with COVID-19 disease in New York City”. The hospitalized cases would have the medical histories already in the data set. For the non-hospitalized cases, they could be called in to collect their medical histories. Then this method would also work with this data set to find effective medications. It’s common to look at collected medical histories and find certain risk factors for bad outcomes of a disease, especially for COVID-19 as that New York report did. Why not look at those medical histories to search for medications with a link to positive outcomes for a disease?
In fact this method likely would work for any of the studies that had cases numbering in the thousands in their data set. But note that I’m also suggesting going beyond just this. With approaching one million COVID-19 cases in the U.S., this would provide an unprecedented degree of data that could be used to search for drug associations to positive patient outcomes.
If this works, then it becomes obvious to take this to the next level to find effective drugs for any disease.
Robert Clark
Unlike Rx drugs which can be linked to a patient, over the counter drugs such as Pepcid-AC have to be self reported and then put into a medical record. This makes it a more difficult task to perform a decent analysis.
We still cannot promptly identify using EHRs across the nation the drugs suitable for repurposing even if they are OTC, recognize risk factors, or display the whole data picture for improved comprehension.
We are facing a disfunctional EHR system that is convoluted by design. The flow of disorganized, non-interoperable generated data leads to unnecesary information overload, confusion, and wasted time to effectively deal with a disease of pandemic proportion.
So therefore, this is a perfect time to create an interdisciplinary team to redesign and reprise and redirect EHR datasets into a present and most importantly future pandemic clinical use such that, most likely using some dedicated supercomputer time and AI, to ensure the ability to access and fully utilize Big Data EHRs. If it is designed well starting today under the present simultaneous COVID Pandemic AND pneumonia/influenza epidemic in the US, we have the potential to more rapidly recognize and provide potential useful data and even eliminate hazardous conditions from patients in the future and eliminate the clear problems pointed out by Ana!! Cheers
At least in the US, this is easier said than done. EHR design is focused primarily on reimbursement issues. This is the primary concern from hospital management who pay for the software. There is a good article by by Sidhartha Mukherjee on this HERE. I hope it is not behind a paywall as it’s a very pointed article. One of the salient quotes, " Finally, we need to acknowledge that our E.M.R. systems are worse than an infuriating time sink; in times of crisis, they actively obstruct patient care. We should reimagine the continuous medical record as its founders first envisaged it: as an open, searchable library of a patient’s medical life.
A key article that attempts to find effective medications by reviewing medical records of COVID-19 patients:
I encourage anyone with medical or pharmacological knowledge to review the medications that appear in the article to see if they jog any bells that would suggest they would be protective or curative against COVID-19.
With 1,000,000 COVID-19 cases in the U.S. now, this would be even more effective if all those medical records could be brought together and reviewed:
Robert Clark
Looking over the medications mentioned in this report I’m surprised and disappointed that hydroxychloroquine wasn’t mentioned. The researchers must have surely been aware of the debate on its effectiveness as a preventative or curative.
The report mentions 12,818 individuals with COVID-19 were tested in their sample with 2,271 (17.7%) testing positive, so 10,547 (82.3%) testing negative.
The number of people in the U.S. taking HCQ is about 6 million, or about 1 in 50 in the U.S. Then we would expect in the range of 1/50th of the 12,818 to be on HCQ or about in the range of 250. Was the percentage of those on HCQ higher, lower, or the same in the test-positive and test-negative groups?
There were 707 of the test-positive 2271 (31.1%) cases that were hospitalized. Did the patients on HCQ of the hospitalized cases have better, worse, or the same outcomes?
Robert Clark
Discusses search for effective medications in the direct sense, by finding commonalities in patients with positive outcomes while undergoing treatment for COVID-19.
Robert Clark
Hello again everyone, I haven’t commented on here in awhile.
In an earlier comment, in reading over that “Safety of Hydroxychloroquine…” preprint I noticed a puzzlingly high percentage of patients taking HCQ for Acute Respiratory Distress syndrome(ARDS):
So I wondered if it was for COVID-19. But @Mark_Shapiro in the following comment said all the data was from 2019 and earlier, so that couldn’t be the reason. I would like this timing to be confirmed though. I couldn’t find it in the report. If some of the data was actually from the COVID-19 period then HCQ use increased multiple times so it would makes sense, IF that were the case.
If not, then we still have a puzzle. Doing a google search, some rheumatic disease patients had pneumonia but it was a not a common occurrence. Then it appears that many doctors were prescribing HCQ for ARDS even before COVID-19.
If so then that is surprising because I did a Google Scholar search and there were very few references of studies where HCQ and ARDS were mentioned in the same paper, and fewer, if any, that discussed HCQ specifically for treating ARDS.
Also, interesting is that the different medical history sources used in the report, coming from insurance records, had differing percentages of HCQ in association with ARDS. Some had in the range of 15%, others in the range of 45%.
This would suggest that different groups of doctors were prescribing HCQ for ARDS more than others. Perhaps in different regions?
But how was the idea spread pre-COVID-19 to use HCQ to treat ARDS? As I said there was very little, if any, reference reports on HCQ for this purpose. But if so many doctors were using it for this purpose there should be published reports describing its effectiveness for that purpose. In my search, not an extensive one, I couldn’t find any pre-COVID-19.
Granted it does make sense since HCQ is an anti-inflammatory. But it’s puzzling there was so little research work describing it for the purpose.
This Is just puzzling all around. We’re constantly hearing about anti-inflammatories of various types being repurposed to treat COVID-19. One of the most notable effects of COVID-19 is ARDS. If it was well known that HCQ was a commonly used treatment for ARDS, and also that it was effective, then clearly it becomes a preferred treatment for COVID-19.
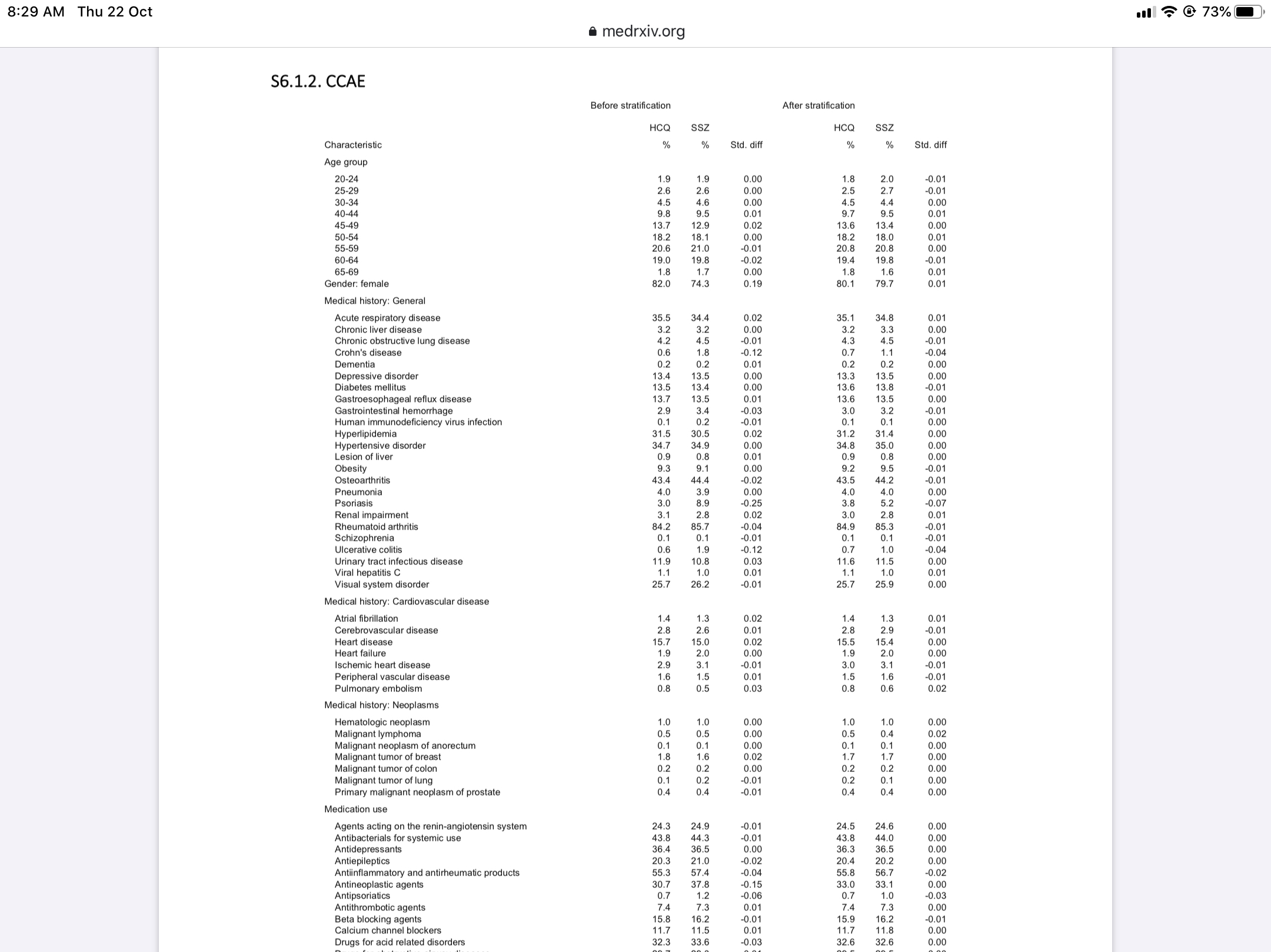
Aside form this issue there was another puzzling aspect of the report. In the Supplementary appendix there is this table:
It gives the percentages of HCQ use compared to sulfasalazine both before and after “stratification”. I assume before stratification means before the data is adjusted to match HCQ and SSZ propensities. But why is it for so many categories the percentages are the same even before stratification?
That would suggest for almost all conditions doctors were prescribing HCQ and SSZ to the same extent, which doesn’t seem likely.
Robert Clark