In reading over the report, “Safety of hydroxychloroquine, alone and in combination with azithromycin, in light of rapid widespread use for COVID-19”, it appears the patients whose data was collected weren’t tested for COVID-19 at the time. So it would take an additional expense to track these patients down and administer COVID-19 tests. In other words, it would not just be a matter of data collating. And even then you wouldn’t know when the patients contracted it.
There is also a puzzling line in the report in Table 1, p. 16 in the list of patient health conditions:
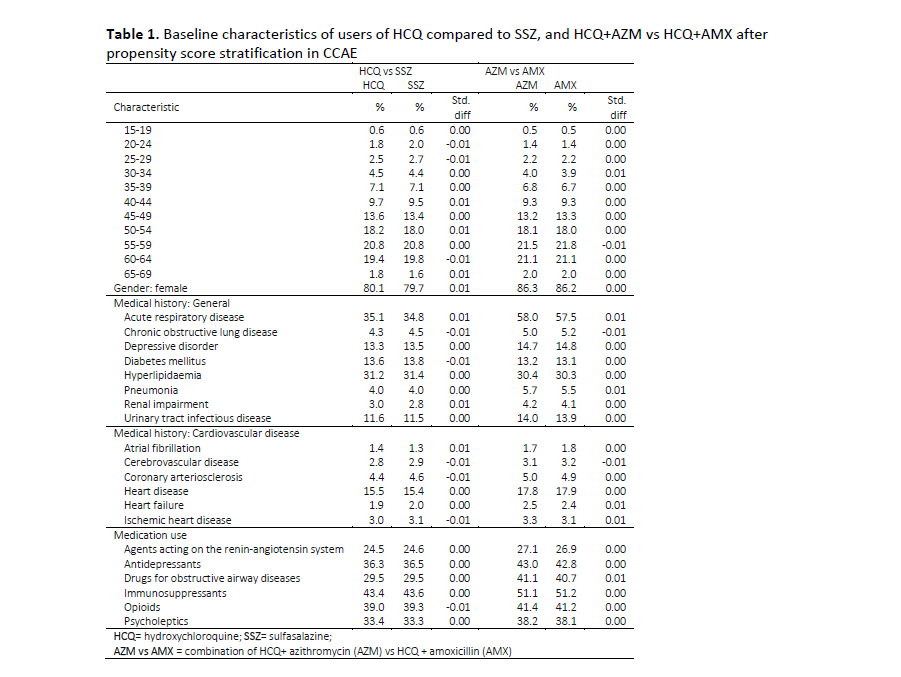
It’s the line in the selection above showing the percentage of “Acute respiratory disease”. The numbers are quite high across the table. But HCQ is now given in the 6 industrialized nations that the cases were taken from for disorders like lupus and rheumatoid arthritis, not for things like malaria. I don’t believe ARDS has a high incidence in those illnesses. So was this high incidence of ARDS because a large number of these cases were taking HCQ as treatment for COVID-19?
That complicates matters if so. Because we’re trying to find cases that were already taking HCQ long term and then see if they contract COVID-19, not those who started taking HCQ because they had already contracted COVID-19.
We might still be able to use this fact however, if we do have access to these patients follow-up health histories. We could see how many recovered from the COVID-19 on HCQ and the various combinations with and without HCQ.
Because of these extra complications I still prefer the idea of the FDA putting out a request to all doctors treating COVID-19 patients to send in their health histories to see how many of them were on HCQ. This would be just a matter of data collating, so much cheaper to do.
Robert Clark