Thanks Martijn.
I will have a look at the Chrome issue, not sure why that happens.
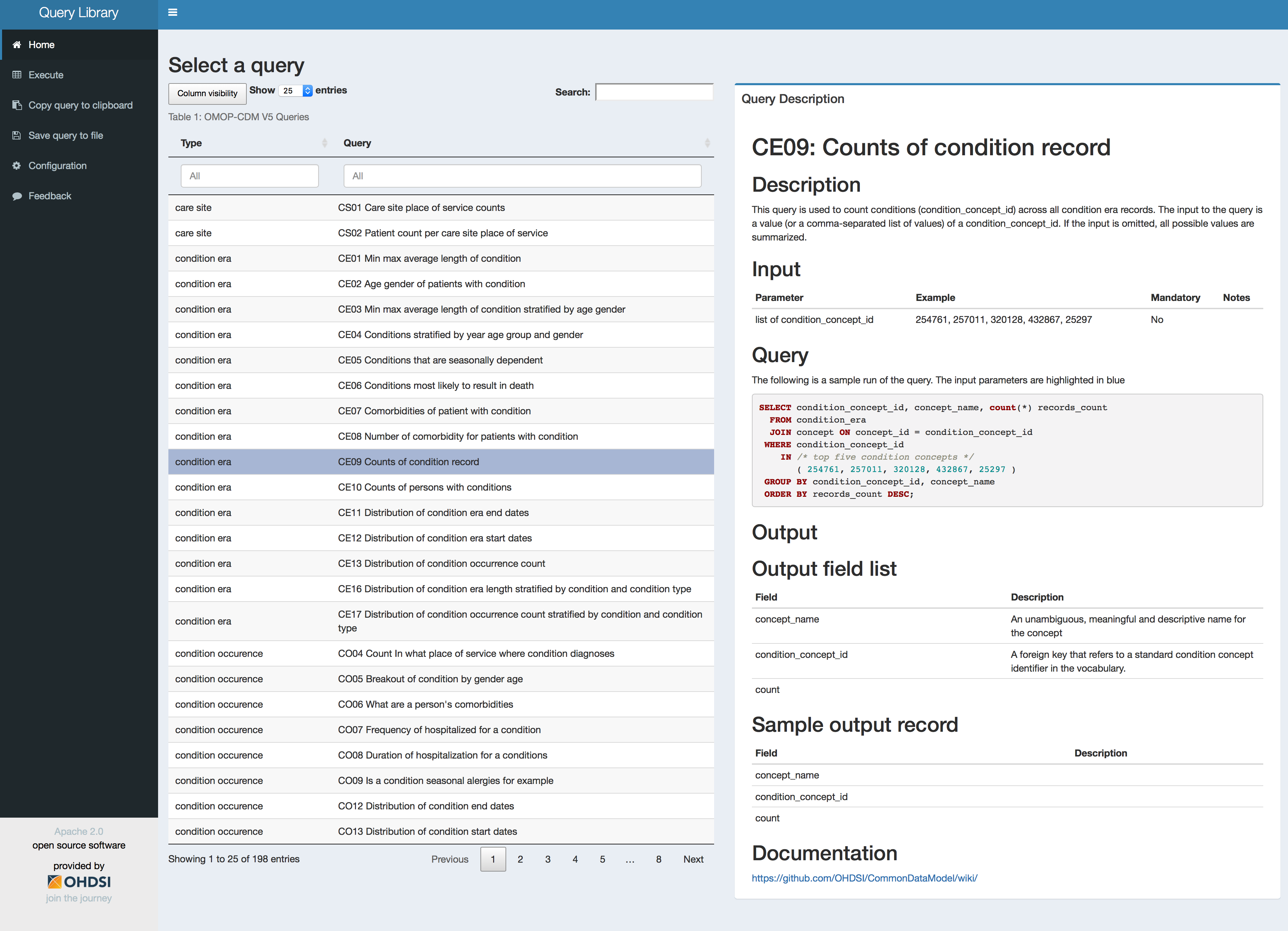
Yes, I agree. The purpose of the library is to have access to often used queries for re-use and also for training purposes, e.g. in a training we can refer to query G04. If there are often encountered questions on how to perform a certain query on the CDM we can add these to the library through Github issue/pull request. We can add a validation procedure by the package maintainer.
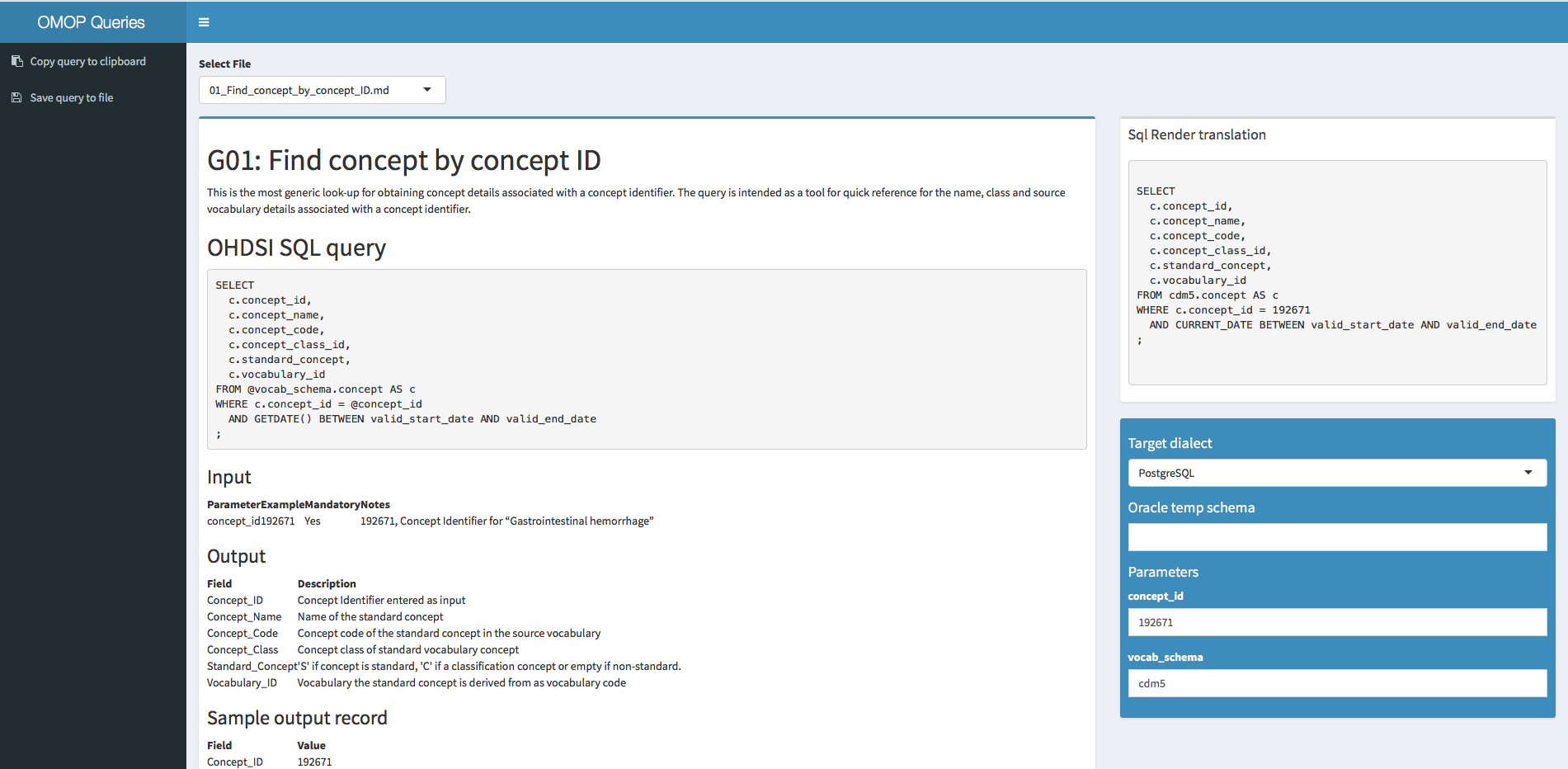
Parameterized SQL is already supported in this version but I have limited this to @cdm and @vocab in the queries that are rendered on the fly using the settings in de configuration tab (see for an example the visit query). It can be made flexible to add a query dependent parameter box but for now I think this is a bit of an overkill.
If you run it locally we could add the option to define a user folder that adds your own queries on top of the once provided by OHDSI potentially, but not first priority now.
I am not so sure about making add/edit query options in the APP itself available (definitely not on the community version that would mean we need to add user accounts etc which is a bridge to far i think).
API i also do not understand @Gowtham_Rao.