
@Chris_Knoll - Will you be able to help me with this scenario?
Hi, @SELVA_MUTHU_KUMARAN,
As a rule, cohort entry events can only be used if they fall within an observation period, so that we can then determine how long the person is in the cohort (by default, it uses 'the observation period end date as the cohort exit date).
Since you are doing this as a demo, you can probably inject ‘fake’ observation_period records based on the min(condition_occurrence_start_date) and max(condition_ocurrence_start_date) + 1:
insert into observation_period (observation_period_id, person_id, obseration_period_start_date, observation_period_end_date, period_type_concept_id)
select row_number() over (order by person_id) as observation_period_id,
person_id,
min(condition_start_date) as observation_period_start_date,
dateadd(d, 1, max(condition_start_date)) as observation_period_end_date,
0 as period_type_concept_id
from condition_occurrence
group by person_id
I do not know which dialect of sql you need, so you’ll have to translate the above to your desired SQL dbms.
This query will create 1 record per person based of min/max of dates in condition_occurrence. If you need to create cohort entry events from any of the other domain tables, then you will have to take the min/max of all the other domain tables (by person) to define your observation periods.
-Chris
Thanks for the reponse Chris @Chris_Knoll. Much appreciated. I understand the need for observation periods in cohort entry criteria but are there any possibilities (do you foresee?) of making it as an optional field?
Hello @Chris_Knoll ,
In addition, when I update the below ‘Target’ items using Public as schema, ‘Cohort’ as table and ‘24’ as id, My sql runs without any issues but still my cohort generation fails. Am I missing anything else?

Update - Found this link. Will try the below solution.
If I still face any issues, will get back to you. Thanks for your time and patience
No. In order to enter a cohort, we need to know the continuous observation before and after the entry event.
@Chris_Knoll - Thanks for your response, The above thread helped us fix the issue and we are abe to generate the cohort successfully now. However, I am facing an issue under ‘Characterisation’ tab.
Can you please help me with the below post?
Thanks
Selva
Check your console’s log (your chrome debug console, ctrl-shift-i on windows) when you load the report. See if there are any errors fetching the report data.
Our cohort characterizations is failing continuously.
- Can you please let us know what can be the reason ? I have attached the json code (.pdf file) from Utilities section for two of the cohorts if that can help
JSON_COHORT_Characterization.pdf (14.1 KB)
astrovastatin_cohort_characterisation.pdf (13.9 KB)
- Can you please let me know whether ‘Feature analyses parameter’ Tab is mandatory? I mean when I leave that field empty as shown in screenshot below, will the cohort characterization fail?
We couldn’t find error message in console log when ‘Cohort characterization’ failed?
However, for cohort characterization which were generated successfully few days back, we get error while report generation. I have attached the screenshots at the bottom
How to generate ‘Cohort Characterization’ successfully without any error?

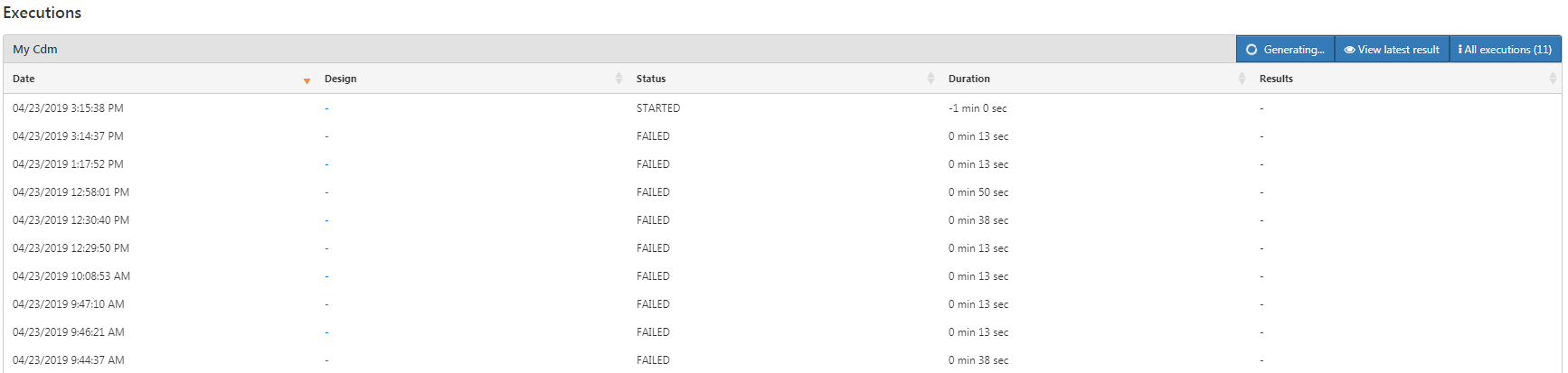
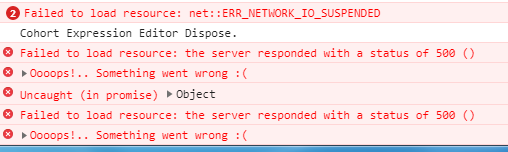
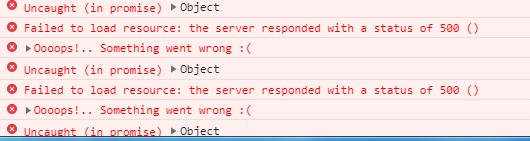
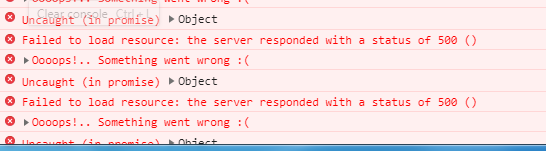
We require your assistance for two things
-
Cohort Characterization - Failed issue
-
Report generation issue - Not sure whether issue 1 is causing this issue. The above screenshots are for this reporting issue. The screenshots are fetched from Google chrome console. Sharing it only to help you get a better understanding of the problem as I am not sure which issue is causing the other
Can you please help us?
Thanks
Selva
The errors shown in your console log is indicating that there was an error retrieving information on the server side. Although, it is not clear which ‘resource’ was requested that resulted in the Error 500 status, since it’s not shown on your console.
The “failed” result of generation also indicates a server-side problem.
To troubleshoot, you can try a two things:
1: From the UI side (in Chrome) if you can look in the ‘network’ tab, you will see the requested resource that failed (Error 500), it will be highlighted in red. You can right click on that request and ‘open in new tab’ and it will make the request to the server, and present the error message. The message may give you information as to the core problem.
2: From the WebAPI-side: you should get the logs and look for exceptions/errors related to cohort characterization. if you search for the text ‘[FAILED]’, that is the text that is associated with a job failing. You will need to look above the job failure message to look for the underlying error. It could be a mal-formed SQL excpetion, or a permission denied error. Unsure, but you need to interrogate the log and look for errors.
Hi @Chris_Knoll
Thanks for your time and help in answering my queries. I believe my team and I are just close to resolving this issue but somehow we don’t get it right.
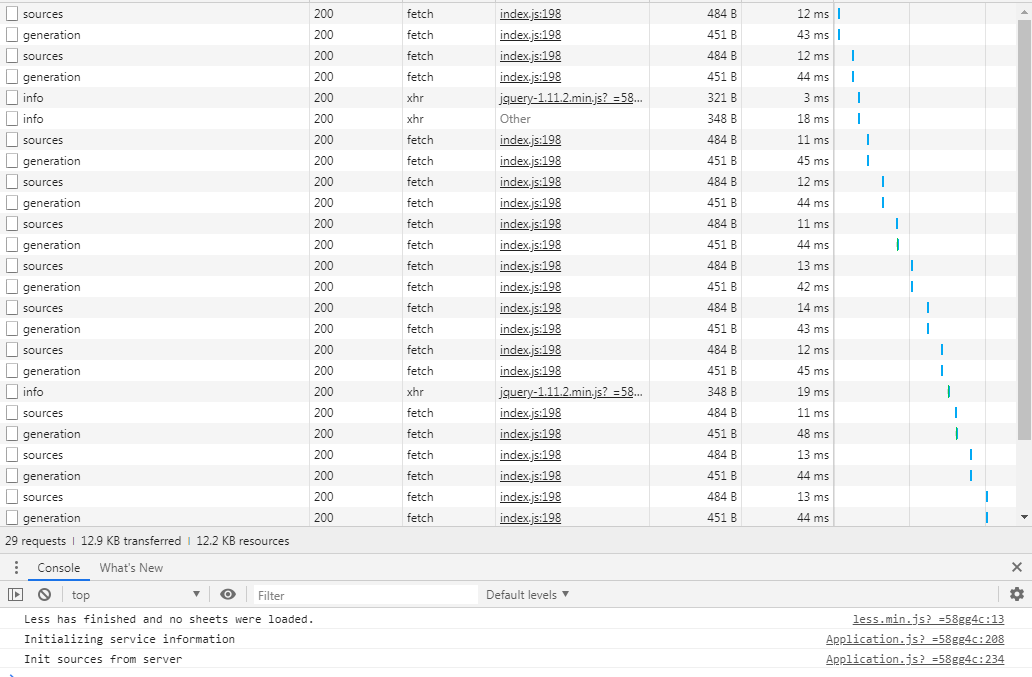
As shown in the screenshot below (t1.PNG), I don’t see any red-color highlighted error message. As said earlier we don’t see any error message when cohort characterization failed. Am I missing anything here?
Does the message at the bottom of the screen indicate any useful information?
Screenshots shows 29 requests, but I waited to validate for rest of the requests but I don’t see any error messages
In addition, I tried again after updating my Atlas/webAPI to 2.7.1, even then the cohort characterization is failing. But when I clicked the “Failed” status button, I was able to see an exception message which I have attached it for your reference. Can you please help us on how to fix this?
Java_Exception_Bad_SQL_Cohort_Characterization.pdf (11.1 KB)
What should we do to fix this issue?
Apologies if my questions are basic, we are quite new to this area/setting up of servers etc.
@Chris_Knoll - We fixed it. cc_results table was missing. Thanks a lot for your time and patience. You are awesome.
In closing, I would like to confirm my understanding of cohort entry criteria for one last time with you.

-
I am looking to build a cohort of patients who had taken ‘Paracetamol’. So I have drug exposure filter with “Paracetamol” concept
-
Can you please help me understand the need of observation period?
Let’s consider my database has patients records from 2008-2013. The criteria that I have set for observation period (7 and 120 days as shown in screenshot), does that indicate that I am trying to understand what led the patient to consume paracetamol by looking at his past history (7 days) and after consumption, we observe him for another 120 days to understand the effect of having paracetamol. Am I right? Is my understanding correct? Can you help me understand this with layman terms? I have no background in healthcare/medical science.
-
We can’t do anything with just having one cohort. Am I right? I mean we can generate summary statistics/or kind of derive some baseline characteristics but we always have to compare our ‘Paracetamol’ cohort to another cohort (ex: people who didn’t take paracetamol or any other related drugs)
-
Limit Initial Events - Gives first (only one) of all records (earliest), last (only one) of all records (latest) and “all events” will give all the events of paracetamol consumption. Am I right?
7 and 120 means you are requiring the person to have at least 7 days continuous observation prior to the exposure record start date, and 120 days after the exposure record start date. You use these settings to enforce that you have enough ‘look back’ time for each person (you may not be able to determine if the drug exposure is ‘new’ if you only require 7 days of prior observation…mabye something like 180d is mroe appropriate. To require 120 days after means the person must have survived 120 days. In certain studies, this would be introducing ‘immortal time bias’ but in other studies (like prediction), it may be appropraite, it depends!
You can characterize it, but yes, for other operations you need a target cohort and an outcome cohort to do things like prediction and incidence rate.
Yes
Hello @Chris_Knoll - We created our own custom concepts for our data. However in Atlas, we found something unusual, so thought of checking with you
- Cohort Generation returns records successfully when I explicitly mention the custom created concept_ids for my observation.
Ex: Here, I have created around 10 records in observation table with my concept_ids in “Value_as_Concept_id” column. When I follow this approach, cohort is generated successfully and returns records. Here HDB 1-2 room and HDB 3-room flat are custom concepts
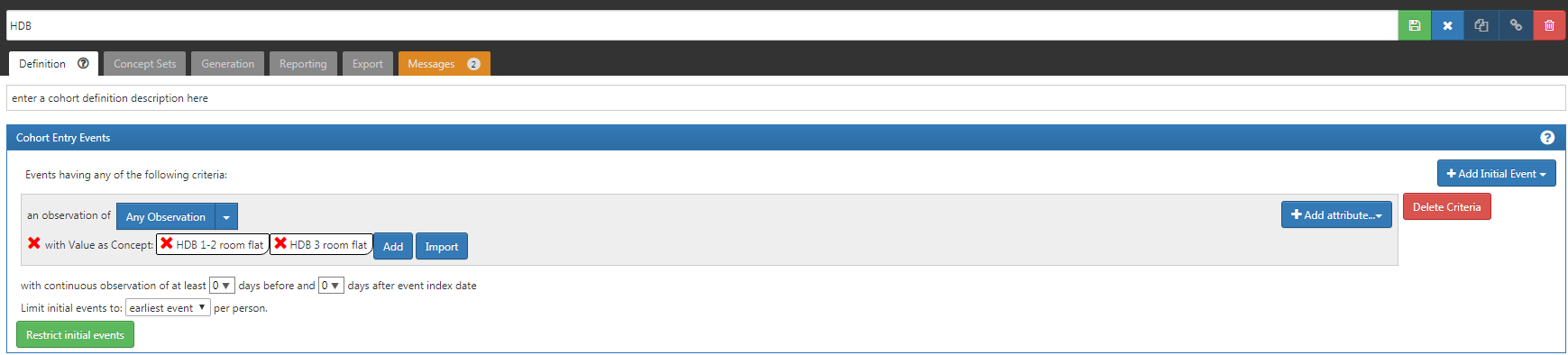
- However, when I create a concept set using the above concept_ids and use them during cohort generation, it returns 0 records. Instead of using the “Add Attribute” option, I am using the concept set (which contains the same two concepts) but it returns 0 records. Can you please help us understand what might be the reason?

-
Finally when we use our custom created vocabulary_id as a search term (ex: Survey_PS) in search field of vocabulary search in Atlas, it does not display all our custom created concepts under the vocabulary Survey_PS. Is this expected?
-
I also tried the advanced filters option where I checked my Survey_PS and clicked on Search Icon (Microscope icon), still it doesn’t return all custom concept records under my vocabulary

Can you please help us with these issues and let us know whether we are making any mistakes?
Thanks
Selva
The first image shows looking for the 2 concepts in the Value As Concept field. The second image shows looking for those concepts in the observation_cocnept_id. What did you put in the ‘observation_concept_id’ for those records?
As far as the vocabulary search, If the values are inserted into the ‘concept’ table, the vocabulary search should find it. You should write a direct query against your vocabulary tables to ensure that you can find the data. If you are saying that you selected the specific vocabulary and clicked on the search icon without typing any search terms into the textbox, I am pretty sure Atlas will not perform the search unless there is at least 3 characters of text in the text box.
Thank you @Chris_Knoll. Thanks for correcting my mistake.
Okay got it. So when we use concept_sets, it filters based on observation_concept_id (Tablename_concept_id ex: Drug_concept_id, Measurement_concept_id)? Am I right to understand that it is because of the same reason that we don’t see these column names in drop down of ‘Add Attribute’. Should we wish to filter records based on these concepts, only way is to concept sets
- Our data is de-identified (Person_ids, dates etc), it’s a hospital EHR records where we don’t have any info about patients before they visited hospital. In our case, do you see any use of observation period window?
is there any way to bypass this observation period (date) criteria or choose a default one which will ensure that all my records would be returned based on my Cohort entry criteria (Concept and default observation period) and inclusion criteria. Atlas allows a window of 1095 days before and 1095 days after event index data. So am I right to understand that it would be best to have this 1095 days window set up to ensure that there is no loss in records?
Thanks
Selva
I wouldn’t say that using concept_set automatically mans you’re taking about {domain}_concept_id, although that is the majority of the cases in the tool. Instead, I would look at is as: when you use a concept set for a criteria attribute, it’s because the intention of the attribute is to allow you to specify a set of cocnept_ids that are built from a concept set expression which involves using elements of concept_ancestor to pull in descendants. So, you’ll provide a concept set for things like the {domain}_concept_id fields, but also {domain}_source_concept. In other places, you would specify a ‘concept list’ which means a literal list of concept IDs which is not derived from any concept_ancestor lookup. Certain attributes it makes sense to ask for the explicit concept Ids (ie: VALUE_AS_CONCEPT: would using concept ancestor for this make any sense? or UNIT_CONCEPT_ID: would using descendants of a UNIT_CONCEPT make sense?). Other places ask for explicit concept IDs where in the future this may change. Example: gender/sex is specified as a concept list (you don’t pick descendants of some gender concept). however, in the future we may have support for ‘gender you identify with’ which you may want to pick a higher level gender identity concept that covers a broader range of lower level concepts. When that comes into the CDM, then we’ll make the change that when you want to check the gender of the person, you don’t specify a list of concepts, and instead you have to define a concept set expression that yields a wider range of gender concepts.
Part of defining a cohort definition is being able to specify the duration from when they enter the cohort and how long they can persist in the cohort. By default, they would persist until their end of the continuous observation period. This means that any event that will bring them into a cohort must exist within an observation period so that we can determine how long they can ‘persist’ in the cohort. Observation Periods make this possible and they are needed for the cohort definition mechanism.
Your comment about ‘Atlas allows a window of 1095 days before and 1095 days after’…is confusing me. You don’t have to enforce that in your definition, the editor is just providing a few ‘presets’ but you could put 123 in the input field. If you don’t want any prior/post continuous observation of the person, just set both those values to 0, and it will require the enclosing observation period to begin at least 0 days before and end at least 0 days after the cohort entry event. But it will require an enclosing observation period.
Determining the Observation Periods in your CDM is one of the most challenging/interesting decisions you need to make about how you want to represent your source data in the CDM. If you make individual observation periods for your hospital visits, then you’ll only be able to design a study that covers the time period that the person is physically at the hospital. Why? Because your observation periods are declaring when you actually have a person under direct observation period, and when you leave the observation period, all bets are off, and you can no longer follow this person for study. However, if you want to declare that your observation periods for patients is between their earliest visit and latest visit, you are sacrificing the ‘truth’ that you have a person under direct observation as a trade off for being able to consider a person for a study that spans across visits.There is no right or wrong answer here, just the consequences of your decision. For claims-based data sources, we use ‘enrollment periods’ to define the observation periods. The assumption here is that if they are covered by an insurance plan, then we will probably know about any relevant clinical experience (drug scripts, diagnoses, lab tests) because there will be a claim for it. Is it perfect? no. You could potentially get some sort of medical intervention that isn’t seen by the insurance provider. It ultimately becomes a limitation of the observational study, and people decide if they will trust the scientific evidence yielded from the analysis or not.
I can not tell you what the right answer is for you. I can tell you that you could easily have 2 different CDMs that have different Observtion Period rules (one would be based directly off visits, where a person has many OPs, and the other uses MIN/MAX of visits, thus giving each person one OP each).
1 Like
@Chris_Knoll - Thanks for the response and I just have a follow up question
Let’s consider the below example from our EHR data (our only data source)
Person ID = 123 has 4 visits to the hospital and they are as follows
a) 1st Jan 2009 - 2nd Jan 2009 - Prescribed Metformin (just for example)
b) 21st Jan 2010 - 25th Jan 2010 -Prescribed Metformin
c) 23rd Mar 2014 - 03rd Apr 2014 -Prescribed Metformin
d) 27th Jun 2015 - 21st Jul 215 -Prescribed Metformin
-
Am I right to understand that drug exposure start and end dates will be same as visit dates or some one spent effort to manually derive their exposure start and end dates from prescription? I mean only these two can be the valid methods to have acquired drug dates considering we don’t monitor patients once they are out of hospital
-
Talking about observation periods, again our visit dates will be the observation periods. Am I right? Hence you have got the equal to condition for dates here as shown below in the cohort query to handle cases like above. Am I right?
-
Let’s say I am trying to build a cohort and I would like to identify patients who have been prescribed Metformin. So, am I right to understand that it doesn’t make sense to use preset interval (1095,365,548 etc) in observation window for our scenario. Because our index date.cohort entry date is the observation period/visit/Drug exposure start date and cohort exit date will be the observation end date/visit/drug exposure end date. These are only date info that we have about the patients.
These intervals would make sense only if I had observed patients outside hospital as well. Am I right? -
So, in this case, all the records (4 records) of person ID = 123 who have been prescribed Metformin will be present in Cohort. So as a ordinary layman I might interpret this as our cohort contains 4 records/4 patients but it is 1 patient occurring 4 times in the cohort. But I think it is possible and valid for a person to occur multiple times in the cohort
-
I understand the meaning of terms like “Latest events”, “Earliest events” and “All events” but can you help me understand how does choosing ‘Earliest events’ or any other be helpful for analysis. This might be an elementary question but your inputs/simple example will be helpful. Or am I right to understand that its basically about whether we want to retain duplicate person_ids or not? Choosing Earliest or Latest doesn’t make any difference?
-
In our case Index date is the Drug exposure date which is again same as visit/observation dates. All dates are equal when we don’t have any info about patients when they are out of hospital. Am I right?
I would not ask my questions regarding min/max visit dates as of now. I feel based on your responses for the above questions, I should be able to make sense of how the min/max scenario works. If I have any difficulty then I will reach out to you. Thank you for all your patience and time in clarifying my doubts. Much appreciated.
This is an ETL specification question. Did you make the drug start/end dates match the visit dates in your ETL? Was the person perscribed a 14 day perscription on the metformin (is it oral?) and therefore the exposure would last 14 days? Are you only considering them exposed if you actively are observing them in the hospital (ie: do you lock them in a room and say 'take all these pills and you can’t leave until you do!)? Will you assume that if you prescribed the drug the patient took all the drug? There is no right or wrong answer here, you just have to decide for yourself what you want to do. I can’t answer this question for you. You have to decide.
Again, the visits will be your observation periods if you decide to do it that way. It’s up to you to make the decision, and live with the assumptions and consequences.
The cohort query you are showing is just applying the ‘prior and post continuous observation’. If you make all your observation periods line up with your visits, then you will never have any prior observation the visit to determine any baseline characteistics. If you look at how you are arranging your observation periods (ie: they are the visits) when someone comes into the hospital, and you can only look at the current observation perod’s events for prior history, you can’t say anything like ‘did this patient not have acute MI event in the past 6 months?’. How know this if you don’t have continuous observation prior to entering the visit for the same observation period? So, that’s the consequence of making Visits = Observation periods. You could make Observation Periods Min/Max of all visits, then you can look at the last visit and consider all the events that happened in the prior visits for this person. If you make one OP per visit, you are eliminating that possiblity. Is it right? Is it wrong? Depends on what you want to do in your study. Again, I can’t answer this question for you.
Yes, it wouldn’t make sense because you don’t allow any prior observation time for your visits. You use the ‘continuous observation’ values to require that a person has been observed for a minimum amount of time if you are going to use the data for the cohort.
Yes, it is valid for a person to appear multiple times in the cohort. We take additional steps that the person has no overlapping time in the same cohort. In other words: if the patient was prescribed a 7 day script for metformin on 1/1, 1/5, 1/14, and 1/20, you can see that there’s overlap between the 1/1 - 1/8 exposure and the 1/5 - 1/12 exposure. If you just used the raw exposure records in the cohort, you would have the person ‘double exposed’ on 1/5, 1/6 and 1/7. But you don’t want that, so the record in the cohort table should show the 1/1 -> 1/27 episode of drug exposure (if you wanted the cohort to represent continuous exposure).
These are used for performance purposes. If you only need to evaluate the earliest event in data, then why bring in all events per person? Reasons to use earliest event per person: new user cohort where they enter the cohort at their earliest exposure and continue in the cohort until end of observation period. Again, it all depends on your scientific question. I can’t answer ‘is it right to do this’ without knowing the context of what you are trying to accomplish.
You don’t have any continuous observation about patients when they are out of the hospital, if that’s how you’re defining your observation periods.
I think you would benefit from the online OHDSI ETL videos, since it’s very difficult to answer in detail your very complicated questions, as well as not knowing the full picture about the details of your ETL to give you the proper response in the right context. I would try to join in on specific work groups so you can ask calls, learn from other people activities, and then leverage that to produce your own fully specified ETL document. The ETL specification will answer all of the questions you raised.
Hello @Chris_Knoll - Just would like to know, if I would like to see the list of members in my cohort, do I have to manually run the query step by step to find out the final cohort set or is there any option to download my cohort members (person_ids)?
Hi, @SELVA_MUTHU_KUMARAN,
The person_ids are stored in the {result_schema}.cohort table. There currently isn’t a mechanism to expose person IDs in the application due to sensitivity to exposing patient level data in the UI. However, you can directly select the person_ids as:
select * from {result_schema}.cohort where cohort_definition_id = {cohortId}
Note: the person_id is stored in column subject_id. The reason for this is that there was the idea that you could create cohorts based on other entity identifiers (such as provider ID) so the ‘subject_id’ moniker was chosen to be more abstract.
1 Like