
Sure, I’ll gather some individuals at SHYFT that worked on a problem like this and we’ll start on a draft proposal.
I just got write access to the Wiki on Monday and I have been preparing a draft in the playground. I’ll put up what I have later today, but it’s still a work in progress.
Draft is now available on Wiki here
Please note I changed the title from “Linking survey data” to “Adding PROM data to CDM”.
@cmkerr: Looks like a decent first draft and it sparked a lot of good discussion in our offices. We are collating our notes and we’ll post those to the thread by EOW for your consideration.
Hello Catherine @cmkerr
Lovely to make your digital acquaintance! I’ve been working with Josh and colleagues throughout the week reviewing this conversation and the proposal that you posted a few days ago. As Josh mentioned, we felt it covered a lot of important bases and provided a solid foundation for the inclusion and support of PRO data.
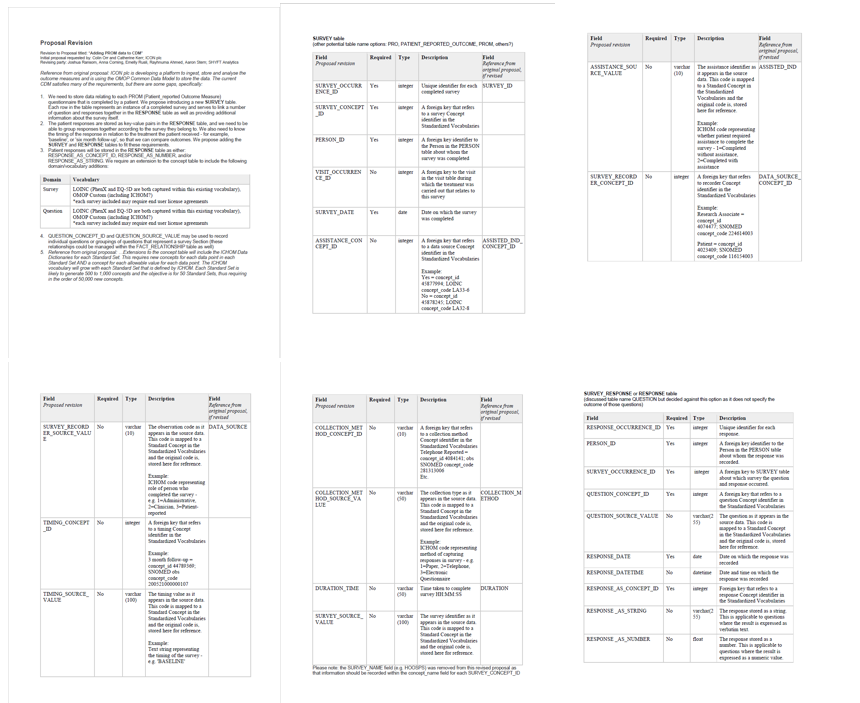
We have a revised proposal, which was built off of your and Colin’s original version. Unfortunately, in order to attach the document I had to condense the 6 pages into one .png, which can still be read when it is heavily-zoomed in  . If needed, we can figure out a way to provide you with a Word or PDF version of the document outside of this thread. I’ll highlight a few of the more prominent edits/suggestions here:
. If needed, we can figure out a way to provide you with a Word or PDF version of the document outside of this thread. I’ll highlight a few of the more prominent edits/suggestions here:
-
After much discussion, we feel that the circumstances warrant the addition of a second table (besides SURVEY), which we have dubbed the RESPONSE or SURVEY_RESPONSE table.
-
You’ll notice that we updated language throughout the document in an effort to better generalize the proposed tables/fields. The intention here was for other organizations to be able to apply this solution to their specific use cases as well. We did preserve the ICON and ICHOM specific examples for reference. Similarly, field/description language was edited to align with current OMOP documentation where possible (e.g. the addition of “SOURCE VALUE” to the source data fields that follow the “CONCEPT ID” fields).
We look forward to hearing your feedback after reviewing our revisions and suggestions! Please don’t hesitate to share thoughts, questions, critiques, agreement, etc…
Best,
Anna
cc: @Josh_R
Hi Anna,
Thanks very much for the detailed response. Unfortunately, I can’t read it properly as I think the resolution was reduced when the png was uploaded. Can you please send a pdf or whatever format suits to catherine.kerr@iconplc.com?
Thanks,
Catherine
I had a feeling that wouldn’t work so well. Thankfully, admin Lee came to the rescue! The ability to attach .pdf and .docx files is now supported - so I have attached a .pdf version. Let me know if you’d like for me to send one to your email as well.
PROMsurvey_SHYFTproposalRevision_20170602.pdf (226.5 KB)
-Anna
Thanks for the pdf Anna - that helps a lot!
Your suggestion to add a RESPONSE table is an interesting one. We did consider that a while back, but felt that the OBSERVATION table was close enough to what we required. Having said that, a RESPONSE table would be even better.
One thing we need to be able to do is to tie PROM data back to an episode of care. For this, we are using the VISIT_OCCURRENCE_ID, so I think we would need that in the RESPONSE table too. Of course, this refers to the visit during which the treatment was carried out, not the visit during which the survey was completed. Make sense?
I notice also that you removed the SURVEY_NAME from the SURVEY table. I guess you intended the survey name to be included in SURVEY_SOURCE_VALUE, which in turn maps to a concept_id for the survey? My SURVEY_SOURCE_VALUE was intended to be an id for the instance of the survey in the source system. I think we need both, but accept that my field names need review.
Cheers,
Catherine
Our group has worked on several survey/registry OMOP conversions and have had to do workarounds for some of the issues you guys are facing. Similar, we stored everything in the Observation table and had our own custom mapping. This really makes the observation very long and as @Christian_Reich mentions, cramming something that really doesn’t fit into the current OMOP model.
I read through the proposal and I like the addition of a Response table because it does separate the responses from the rest of the other observation related data. We have a project where the observation table was very long and overloaded because we combined two data sources, one being the survey/registry data. Having a separate response table would keep things cleaner in this case.
Many thanks for your comments, Mui and Catherine! @mvanzandt @cmkerr
Catherine – in response to your reactions:
Regarding VISIT_OCCURRENCE_ID: we did maintain this FK in the SURVEY table as your team originally proposed. A record in the RESPONSE table cannot exist without a ‘parent’ SURVEY record (via the SURVEY_OCCURRENCE_ID FK in the RESPONSE table). Therefore, we did not include the VISIT_OCCURRENCE_ID FK in the RESPONSE table. Breaking this down, we ultimately have the following questions/options:
- Do we want to attribute an entire survey to a single visit, and individual responses to that same visit? If yes, VISIT_OCCURRENCE_ID should reside in SURVEY only.
- Do we have no concern for tying a survey to a visit, but rather we want to attribute individual responses to separate visits? If yes, VISIT_OCCURRENCE_ID should reside in RESPONSE only.
-
Do we want to attribute an entire survey to a single visit, and individual responses to multiple, different visits? If yes, VISIT_OCCURRENCE_ID should reside in both SURVEY and RESPONSE. This sounds like the ideal solution for your specific use case. However, does this potentially pose integrity issues between visits? Perhaps we could consider a different naming convention within the RESPONSE table, such as value_as_visit, etc.? Additionally, is this universally applicable to a broader group of use cases?
→ Would you be willing to set up a call to discuss this item further? We believe we have a good understanding of your use case and why the visit-by-response would be necessary, but we would like to confirm our understanding and discuss broader use cases as well. Please let us know!
Regarding SURVEY_NAME: we originally noted within the document that “…the SURVEY_NAME field (e.g. HOOSPS) was removed from this revised proposal as that information should be recorded within the concept_name field for each SURVEY_CONCEPT_ID.” After reading your comment that you intended the SURVEY_SOURCE_VALUE to represent the ID within the source system, we revisited this section of the proposal and realized that we overlooked one important piece of this situation. Let’s take a step back here: How are the source_value fields and occurrence_id fields utilized within the other CDM tables? Generally:
- The source_value fields provide the source code or source name that were mapped to the domain-appropriate concept_id.
- The occurrence_id fields provide a unique ID that is generated during the conversion itself (or, where appropriate, this ID may match the unique identifier within your source data).
→ This doesn’t actually leave room for the source data’s unique identifier to be otherwise represented in the final converted table. In our initial response, we overlooked this item, and have updated the proposal revision to reflect that the SURVEY_SOURCE_VALUE should in fact provide the name or code of the source survey. Along the same lines, it is our understanding that it is not necessarily an OMOP standard to report the source data’s unique identifier (unless it is used as the occurrence_id), and it seems prudent to maintain that structure with this proposed table addition to the CDM.
Thoughts?
-Anna
Good points @anna_corning
My initial thoughts on your proposal were based on a comparison of the RESPONSE table with the OBSERVATION table and the VISIT_OCCURRENCE_ID jumped out as something important that was missing. In hindsight though, you are absolutely correct - if the VISIT_OCCURRENCE_ID is in the SURVEY table and the SURVEY_OCCURRENCE_ID is a foreign key in the RESPONSE table, then we don’t need VISIT_OCCURRENCE_ID in the RESPONSE table as well. I can’t think of any use case where we would need it in both.
To explain what we are doing a little more…
The ICHOM standard sets include data from three different sources - Administrative, Clinical and Patient-reported. The latter can always be linked back to a survey, but the first two are not linked to surveys and we will continue to store them as name-value-pairs in the OBSERVATION table.
Regarding the SURVEY_SOURCE_VALUE, my intention was that it would be used in a similar way to PERSON_SOURCE_VALUE - i.e. as a means of connecting the converted data to the original source data. In our case, we ingest data from different suppliers (institutions and registries), load the data into the OMOP CDM, run a number of data quality (DQ) procedures on the OMOP data and report back to the data supplier on any issues. In the DQ report, we need to give them the original keys that they provided and not the OMOP-generated keys. This doesn’t just affect survey ids, but affects visit (episode) ids and procedure ids too.
Point taken thought that the XXX_SOURCE_VALUE fields are used to map to domain-appropriate concept_ids (except PERSON_SOURCE_VALUE is not mapped to a concept_id).
I’d be happy to have a call to discuss. Send me your (and others) contact details to catherine.kerr@iconplc.com, with suggested times and I’ll set something up for next week. We are in Ireland, so I guess afternoon BST would be best. Thanks!
Hello all, @cmkerr @ColinOrr @mvanzandt
Thanks for taking the time to join our quick phone call earlier this week. Following our discussion, we have updated the proposal to reflect the decisions made by the group - see attached. Updates include:
SURVEY table:
- Re-instated field to capture the source data’s unique survey identifier; SURVEY_SOURCE_IDENTIFER
- Added fields to capture whether the survey is validated; VALIDATED_SURVEY_CONCEPT_ID and
VALIDATED_SURVEY_SOURCE_VALUE
RESPONSE table:
- Added field to capture responses as datetime; RESPONSE_AS_DATETIME
- Added fields to capture the low and high end of the expected response scale; RESPONSE_RANGE_LOW and RESPONSE_RANGE_HIGH
Outstanding question: on the call we briefly discussed the need to capture the response type e.g. ‘number scale’ vs. ‘free text’ etc. Is this a necessary data attribute to capture, and if so, would the best option be a RESPONSE_TYPE_CONCEPT_ID and corresponding RESPONSE_TYPE_SOURCE_VALUE?
Thanks,
Anna
cc: @Josh_R @Astern @rayhnuma @erusli
PROMsurvey_SHYFTproposalRevision_20170616.pdf (234.7 KB)
Anna,
I didn’t get the attachment!! Can you resend please.
Thanks,
Colin
Hi everyone,
Proposal has now been updated on Wiki. Bit of a nightmare formatting all those tables  Let me know if I’ve missed anything.
Let me know if I’ve missed anything.
Cheers, CK
Regarding the response_range_low and response_range_high. What are thoughts about moving this into a Response table and renaming this the Response Occurrence table? To me, these are attributes of the response and if we wanted to normalize this, we shouldn’t be repeating it in the current response table.
Regarding the type of answer, not too sure we need to store this especially since we have that information in the value as fields.
@mvanzandt
Are you suggesting that we have a RESPONSE table containing some kind of validation metadata for each survey question? I can see the benefit of that. For our use case (ICHOM data), most of the responses are categorical variables and each allowed response has it’s own concept in the CONCEPT table, so that provides some validation. However, we do have a couple of questions that expect a numeric response. The range columns were not part of my original proposal because we didn’t really have a use case for them, but the Shyft people did I think, so they may be better qualified to answer this question. I certainly take your point about normalizing the data.
CK
@cmkerr
Yes, that is what I’m suggesting. We have use cases for it, but they are more for application development or validation purposes and not true analysis.
When we do the ETL conversion, if we had the min/max information, we can verify that the values are all within the min/max. If they are not, we can determine how to fix the issue.
For application, when someone is trying to filter on the response, the UI can stop the user from putting in anything outside of the min/max.
For the benefit of the community - the wiki link seems to be this one:
http://www.ohdsi.org/web/wiki/doku.php?id=documentation:next_cdm:add_survey