
Just thinking further about metrics for assessing CIs.
If we are really interested in effect estimation, then want confidence intervals w.r.t. true value:
-
coverage
-
mean CI width
-
variance of CI width
-
bias (point estimate or CI midpoint versus true value)
-
see Kang and Schmeiser CI scatterplots [1] (e.g., CI half width versus midpoint)
(they are much like Martijn’s scatter plots)
If we want to discover associations, then we want confidence intervals w.r.t. no effect (1), and the true value is irrelevant other than its direction:
-
this is really just a hypothesis test (p-value)
-
specificity is set at .95 (95% coverage of negative controls after calibration)
-
sensitivity is proportion of excluding no-effect (1) for positive controls
can derive relation of sensitivity to CI: (CIwidth / 2) < EffectSize - 1 -
ROC area calculated based on point estimate of specificity and sensitivity
(or perhaps could generate curve by altering alpha .2, .1, .05, .03, .01)
Just noticing that when we do p-value calibration and report coverage, we really should also report power on positive controls.
- Keebom Kang, Bruce Schmeiser, (1990) Graphical Methods for Evaluating and Comparing Confidence-Interval Procedures. Operations Research 38(3):546-553. http://dx.doi.org/10.1287/opre.38.3.546
George
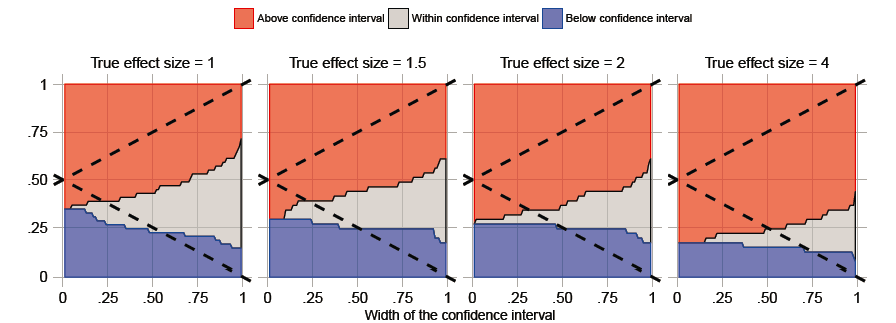
 ).I did add mouse-overs for the scatter plots. I agree that despite the danger of post-hoc rationalization it can be helpful to know exactly which controls are problematic for a particular method. I also added the ROC plots, fixed the ‘True effect size’ dropdown, and added a line (above the metrics table) stating how many positive and negative controls were used when computing the metrics. This might be a good time to point out that the number of controls used is limited by things like the MDRR and stratum of choice. Some methods may not have estimates for all controls (expressed in the ‘Mis’ column) in which case those estimates are considered to be RR = 1.00 (95% CI: 0-Inf) when computing the various metrics.
).I did add mouse-overs for the scatter plots. I agree that despite the danger of post-hoc rationalization it can be helpful to know exactly which controls are problematic for a particular method. I also added the ROC plots, fixed the ‘True effect size’ dropdown, and added a line (above the metrics table) stating how many positive and negative controls were used when computing the metrics. This might be a good time to point out that the number of controls used is limited by things like the MDRR and stratum of choice. Some methods may not have estimates for all controls (expressed in the ‘Mis’ column) in which case those estimates are considered to be RR = 1.00 (95% CI: 0-Inf) when computing the various metrics.