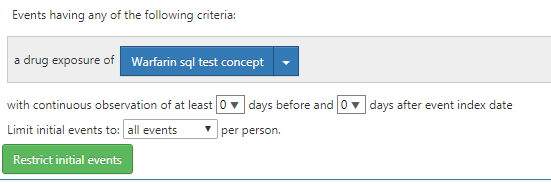
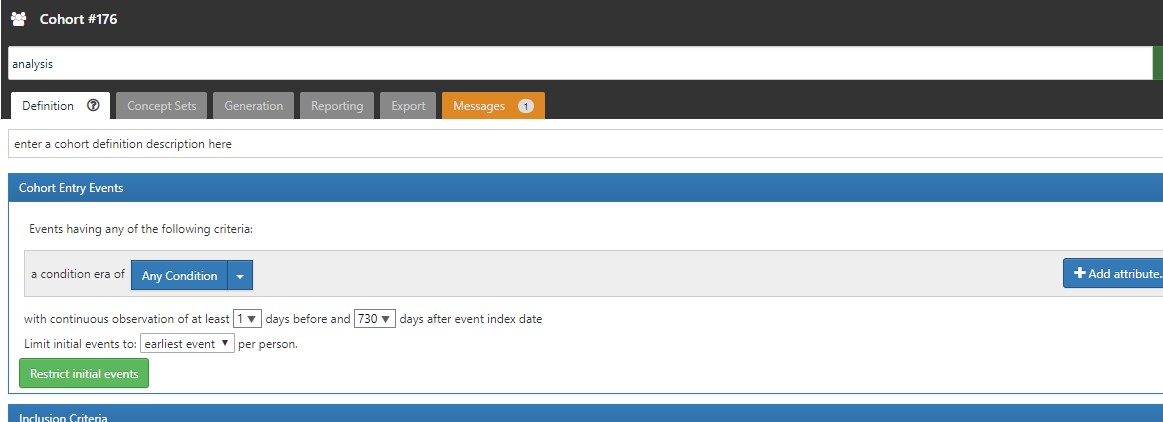
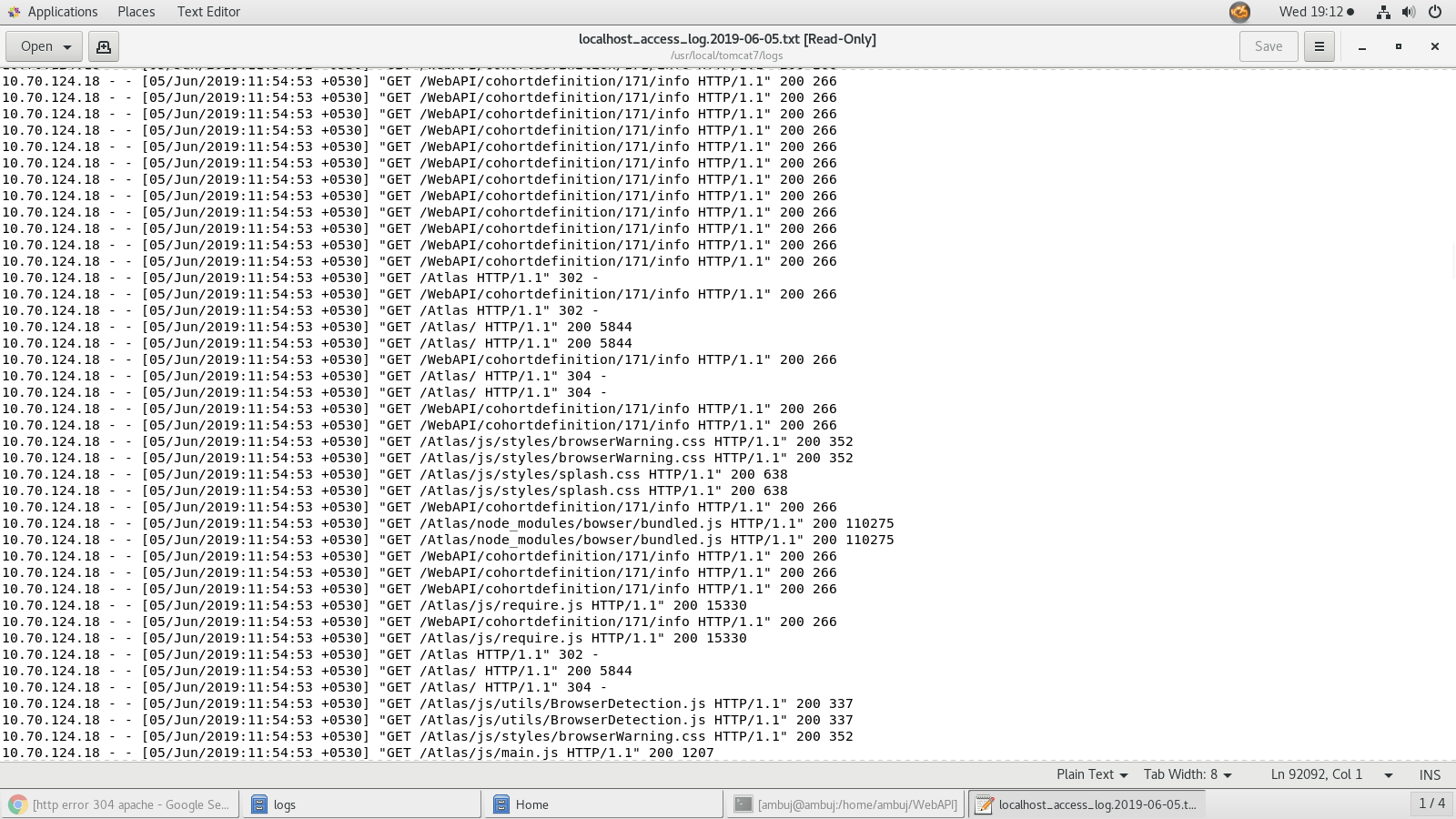
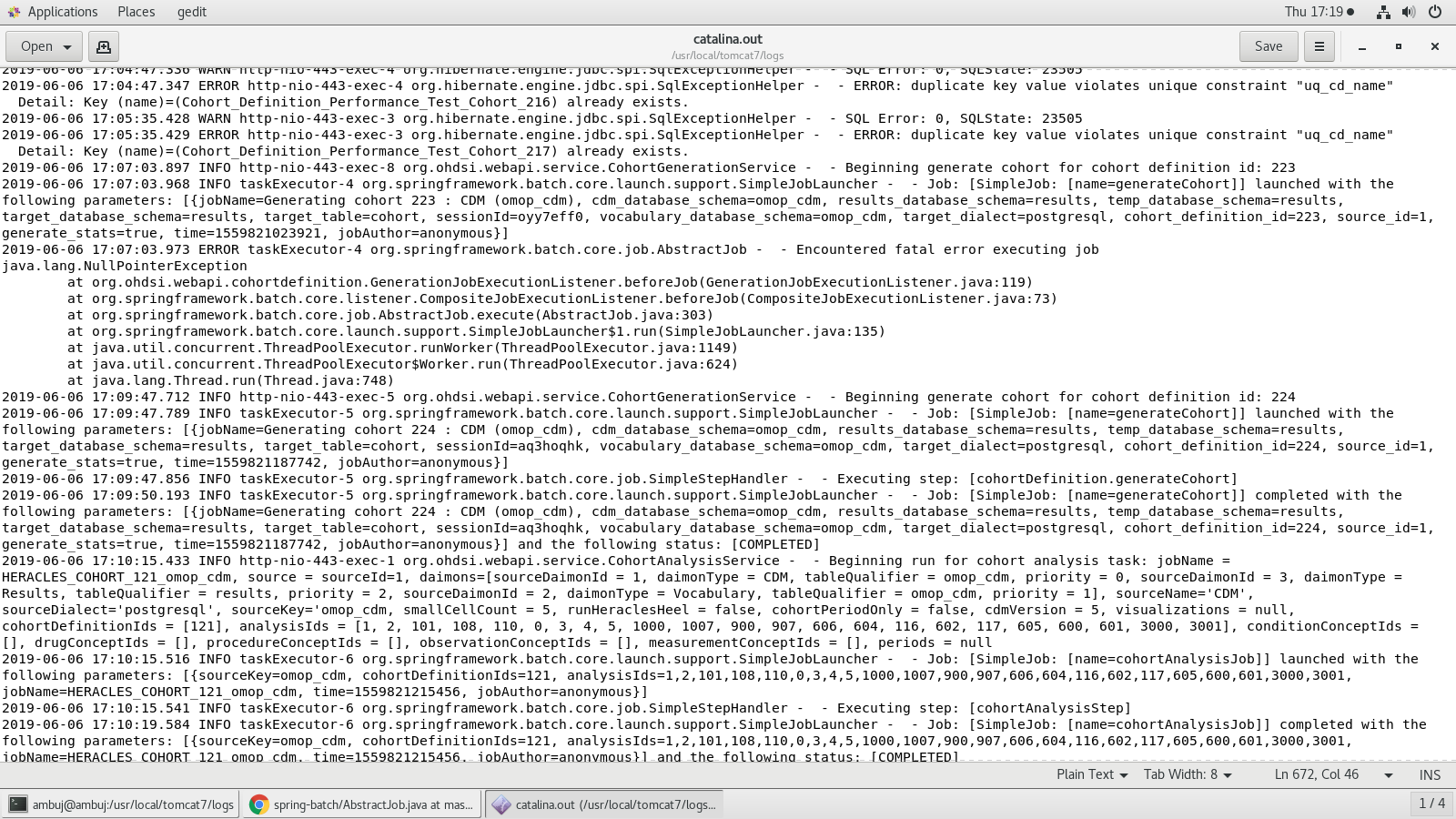
The replacement tokens comes from the ohdsi.source_daimon table. The @vocabulary_database_schema will use the cdm’s schema in the event that the soruce_daimon table doesn’t declare a Vocabulary daimon table qualifier.
Long story short, you can ignore all the settings in docker-compose, just replace @cdm_database_schema with your cdm schema, and @vocabulary_database_schema also with your cdm schema (unless you have an environment where you put your vocabulary tables in a separate schema. I’m assuming you did not since this is coming from Broadsea.
Then run the script and try to determine where the failure is.
-Chris