Dear colleagues,
As I mentioned earlier, we decided to convert whole Korean cancer patients data into CDM from National Insurance data (2007-2017).
I will extract three components of information from this as the first research:
- Quarterly incidence of each cancer from 2008-2017 according to the birth year (5-year base) and sex (and hopefully ethnic groups)
- All-cause mortality within 1-year, 3-year and 5-year after cancer diagnosis from 2008-2017 in these quarterly cohorts according to the birth year and sex (and ethnic group)
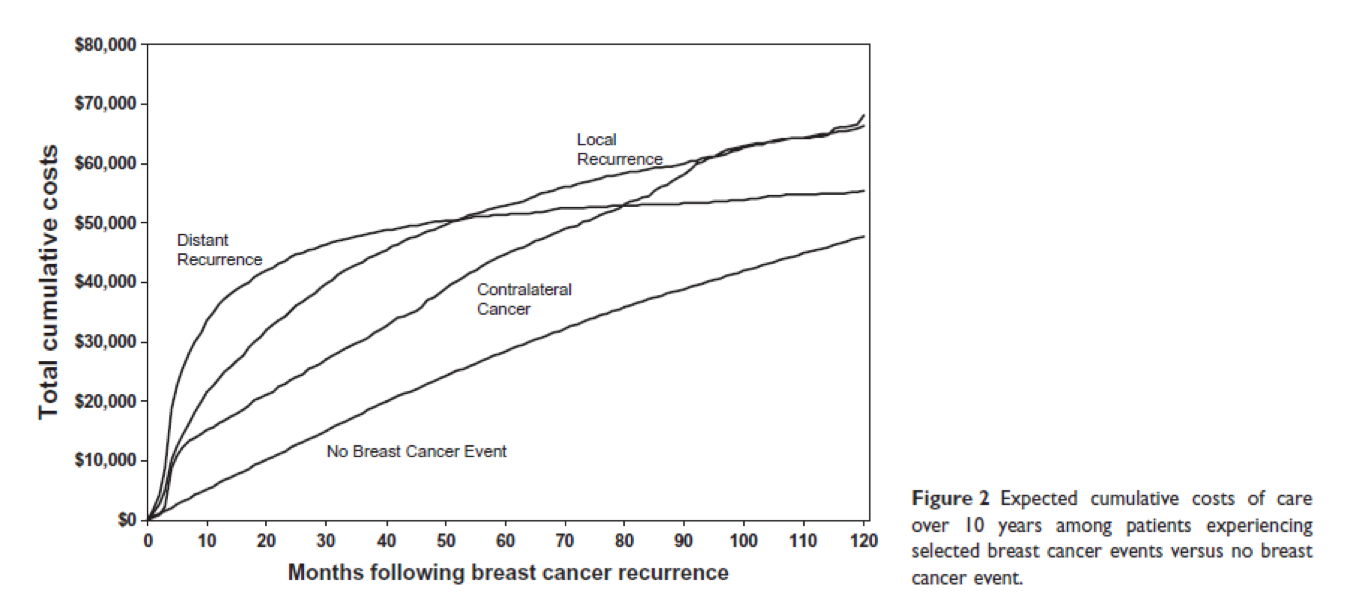
- Whole medical expenditure, cost amount paid by insurer, cost amount paid by the patients within 1-month, 6-months, 1-year, 3-year and 5-year after cancer diagnosis from 2008-2017 in these quarterly cohorts according to birth year and sex.
This looks like ACHILLES (Automated Characterization of Health Information at Large-scale Longitudinal Evidence System), I want to call this project ‘Onco-Achilles’
We can answer to the following questions by this:
- Identify trends of cancer incidence according to birth year and sex. Like Jemal et al., suggested in the NEJM paper, we can describe incidence of lung cancer among young women compared to men across OHDSI network (I feel the incidence of lung cancer and breast cancer become higher in young Korean women).
- Compare the survival trends of each cancer according to the birth cohorts, insurance types and different countries.
- Describe the trend of total cost, cost paid by insurer, cost paid by patients after cancer diagnosis.
- Overall, identify the strength and limitations of health care system for oncology patients in terms of incidence, mortality and economic burden
- The overall impact of novel treatment on the survival and the cost for cancer patients.
- Definitely, the result from this study will be stepping stone for future oncology research in OHDSI.
If you can join this research, please let me know. @Gowtham_Rao @Patrick_Ryan @rchen @rimma