I am new to OHDSI- mainly been a fly on the wall learning more about the group and their interests. But I feel this group has the expertise to provide me with some help.
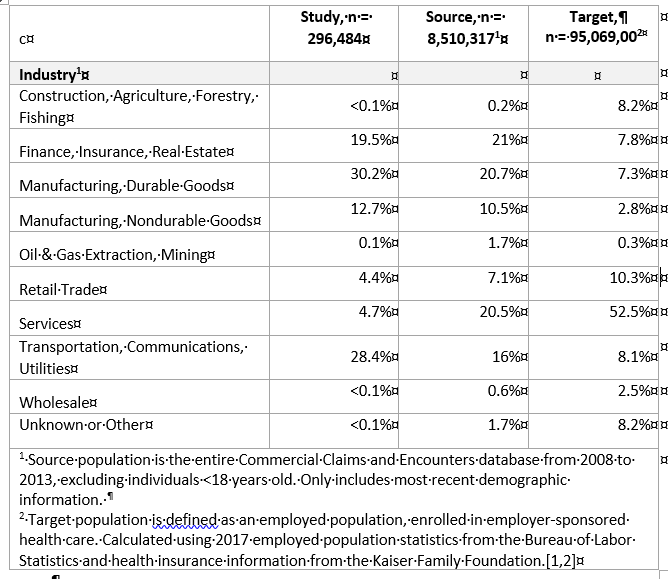
I have done several retrospective claims analyses but a lingering issue is selection bias. I use Truven’s Commercials Claims and Encounters database but the demographics in that database does not match it’s target population (employed with employer sponsored health insurance).
Can someone point me in the direction of a good paper that addresses this selection bias issue? Specifically, how does one statistically adjust their estimates to match the population of interest when you have to use external data to understand that population of interest.
I’d be happy to discuss/elaborate more if needed.